Completely Distributed Peer-Peer Load sharing
The Problem statement
We have ‘n’ resources R1,R2,R3….Rn which can be any of ‘k’ type RT1,RT2,RT3…RTk which arrives as a stream of events. The stream of events are the CRUD operation on these resources. Each of the events are idempotent and self contained. They carry all the information needed to get processsed. The problem is to build a completely distributed peer-peer load sharing system among the processing nodes.
Constraints
The resources can arrive in anyorder of any type. The same resource can arrive one after the other in the queue. The final update of the resource has to be consistent. The underlying processing nodes should be scalable up/down. The processing Nodes can go down any time. The processing nodes should be stateless.
Note that the processing nodes are all running and pulling events from the queue parallelly.
Solutions
Solution1: Single queue multiple processing nodes:
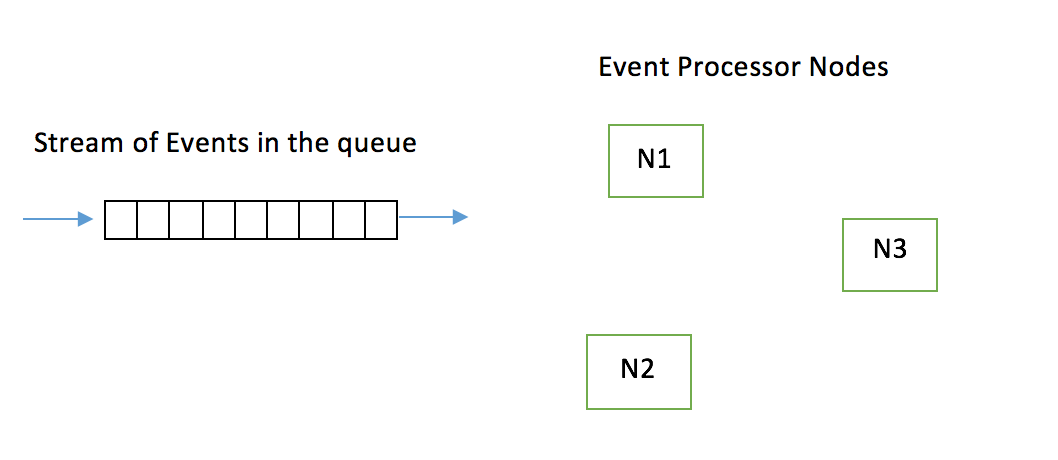
The simplest solution is to have a single queue and all the nodes pull events from the queue. The only problem with this approach is if there are events for same resource together in the queue, then multiple nodes will pick and process these resources. The final outcome of the processing is dependent on the order in which the nodes process the resource.There is a possibility that the final result after processing be inconsistent.
Solution2: Hashing
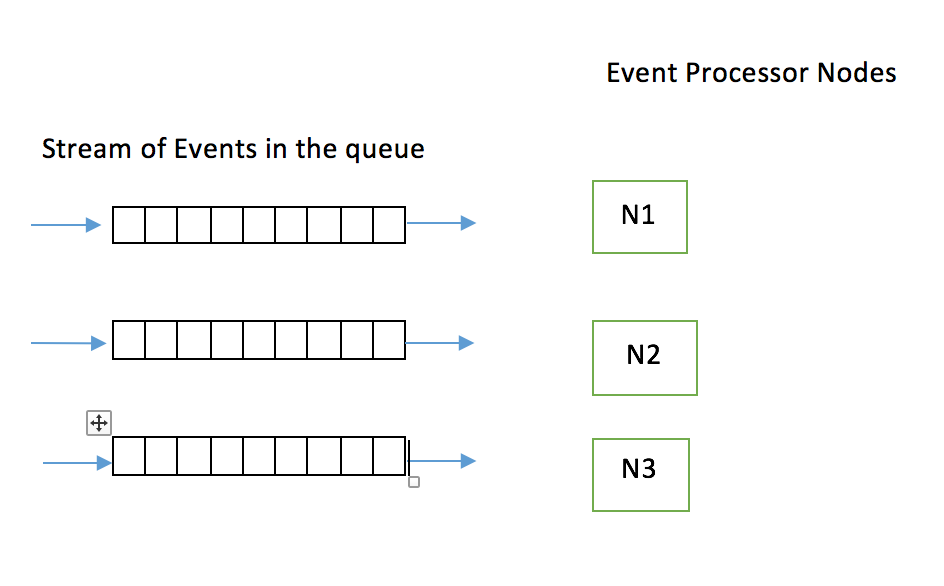
The other way is to have separate queues for each of the nodes. The assumption is that the events are replicated in all the queues and also the order is maintained.Many distributed queuing technologies like RabbitMQ/kafka provide this feature.This is illustrated in the above image.
Now each of the node decide whether to process the resource or not.One way to decide is by using a hash function which provides a hashvalue.Also each of the node agree on a range of hash values that they are responsible for processsing.
Here are the steps across all nodes.
1. Get the resource from the queue.
2. Compute the hash value for the resourceID
3. Check if the hashvalue is in the range.
4. If true process the resource
5. If false reject the resource
6. Get the next resource from the queue
7. repeatFiguring out Hash Range in each node
One way to decide the hashrange is by finding the number of nodes in the processing cluster and figuring out the hashrange themselves.This itself is a bigger topic of discussion.One simple strategy is to assign a sequence ordering number to nodes as they are added.(Even the nodes can pick the sequence numbers themselves as they are added to the cluster) Depending upon the number of nodes and their own sequence number they can compute their own hashrange.Everytime a new node is added all nodes compute their hash range.
However there are a lot of subtleties and edge cases that needs to be taken care here.
Edge Cases in Hashing Approach
-
When the node dies in the middle of processing. All the resources that fall under the hash range of this node will not be processed untill the node comes back. When the node comes back or a new node is added[which is the same], while selecting the sequence number it should select the empty slot and resume processing the resources from that queue.
-
Adding a new Node to the cluster Adding a new node to the cluster is also carrying a subtle side effect. According to the Hashing approach, when a new node is added all the nodes recompute their hashrange. If you think for a minute and workout, we can clearly spot a problem. Since the hashrange is changed, all the nodes start dropping the resources that belong to the new node [i.e. the nodes start droping the resources which are not in their range which might have been in their range before]. As a result all the updates of resources falling under the new node are lost. A new node has to be added only when all the queues are empty. Clearly this is not auto scalable since we would like to add a new node when there is lot of load in the system.
-
Picking the sequence number When more than one nodes are added,we should make sure that not more than one node should take the same sequence number.
-
Figuring out the number of nodes There needs to be a way of finding out the number of nodes in the cluster whenever the cluster is updated.A very complicated and best way figuring out the cluster details is by gossiping(similar to the gossip protocol in cassandra) where the nodes gossip among themselves to know each other.A simple approach of service discovery in consul can also be used to figureout the number of active/dead nodes int he cluster.Or a simple node registry and healthtoken refresh policy for that node rercod in database can also be used.
Solution3: Dynamic queues
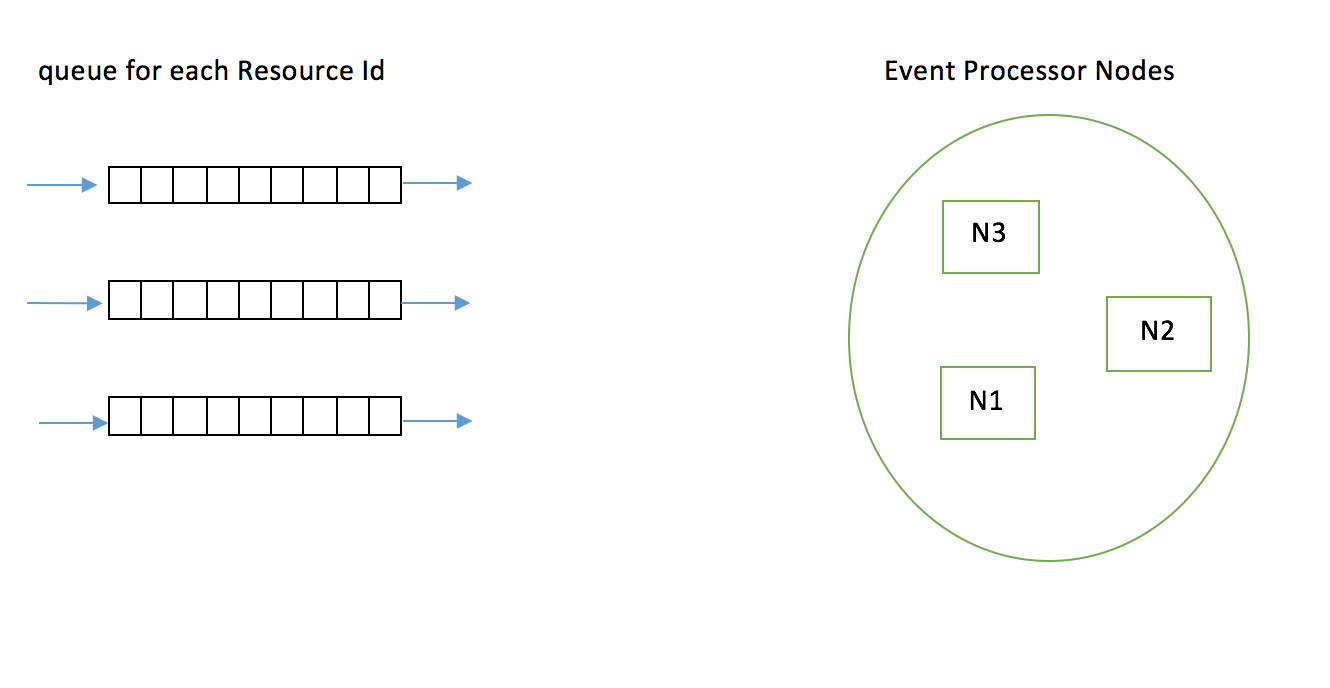
The idea here is to have a separate queue for each resourceID. All the updates of that resourceId are all placed in the same queue. Hence all the updates of that resource are processed in order. Now it is the responsibility of the producer to create the queue for each resourceId if the queue for that resourceId doesn’t exist. Once the resourceIds are created and placed in queue, the processsing nodes
Check to see if there is any queue to which no other node has attached.On finding the queue, attach to that queue and start processing that resourceid.
We see that auto scaling up/down will have no side effects on the system.Even if a node dies in between, other node can attach to that queue and continue from that point.
Drawbacks Clearly one of the main drawback is creating so many number of queues.We also need queue deletion once all the resourceIds in that queue are processed.This approach puts a lot of load on the queue manager.