Distributed Dependency Resolution
The Problem statement
We have ‘n’ resources R1,R2,R3….Rn which can be any of ‘k’ type RT1,RT2,RT3…RTk which arrives as a stream of events. The stream of events are the CRUD operation on these resources. Each of these events are idempotent and self contained. They carry all the information needed to get processsed. Lets say we have a dependency template that says the dependency relation among the resourcetypes as shown below.
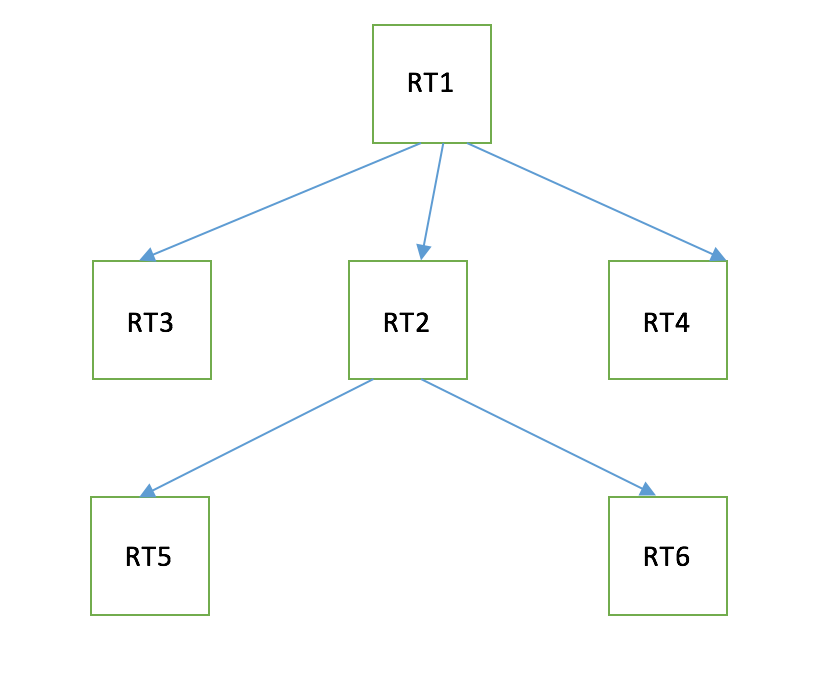
Example:
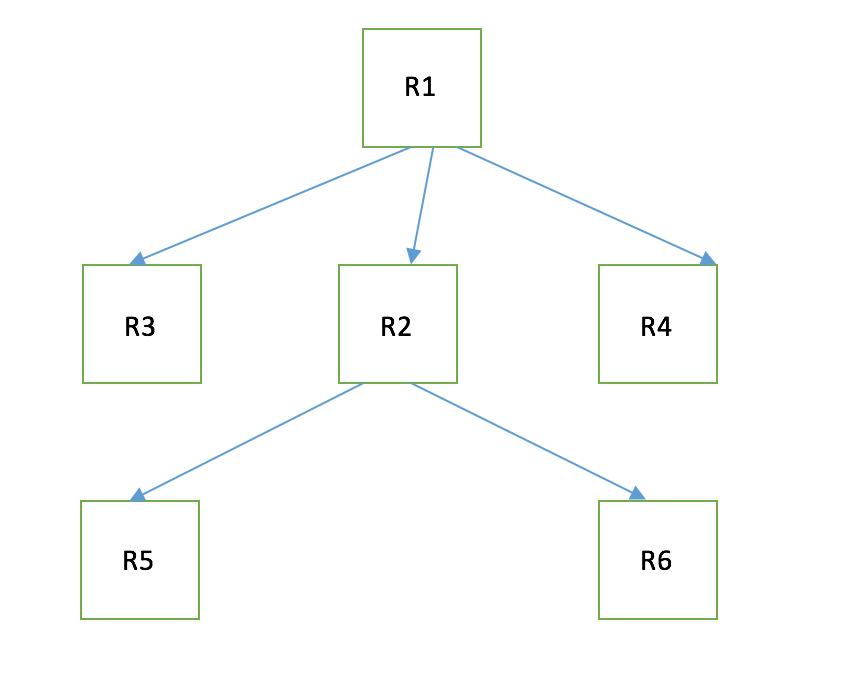
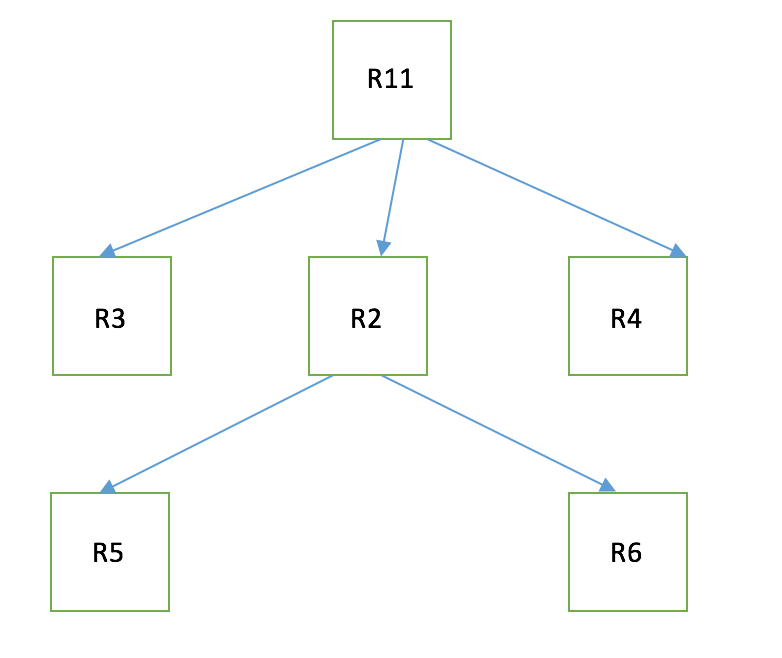
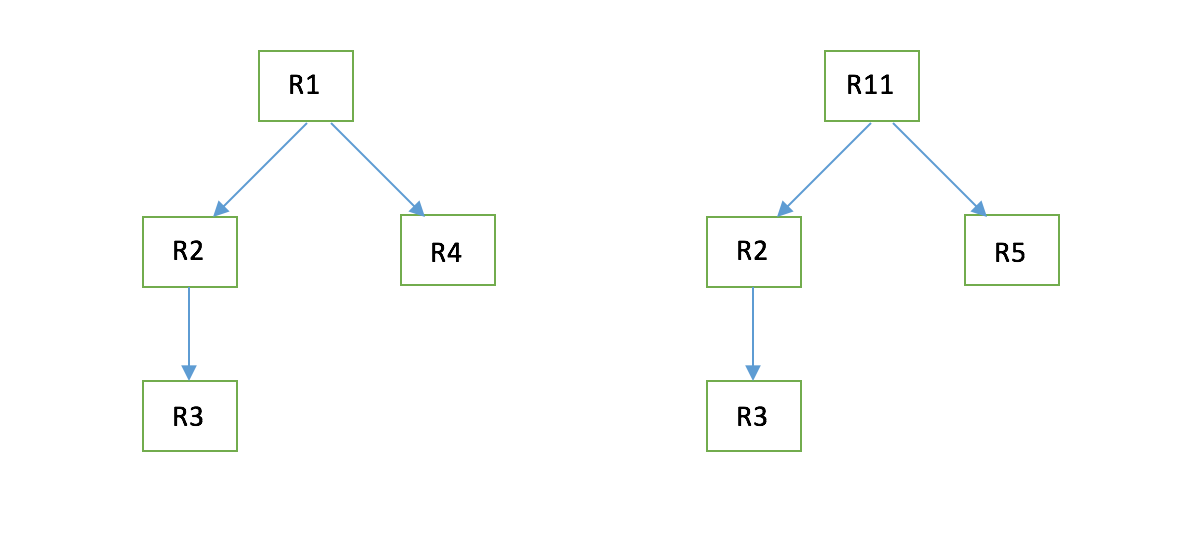
Let say we have a set of resources R1,R2,R3,R4,R5,R6,R11.
R1 = RT1
R11 = RT1
R2 = RT2
R3 = RT3
R4 = RT4
R5 = RT5
R6 = RT6Dependency graph is as shown below for R1.
Dependency graph is as shown below for R11.
Constraints
The resources can arrive in anyorder of any type. The same resource can arrive one after the other in the queue. When a resource of type RTk arrives and if it is insert/update, it can complete many graphs. When a resource of type RTk arrives and if it is delete, it can incomplete many graphs. The underlying processing nodes should be scalable up/down. The processing Nodes can go down any time. The processing nodes should be stateless.
Note that the processing nodes are all running and pulling events from the queue parallelly.
Story
Lets build the problem statement in a more granular level. Lets assume that the event processing nodes pull the events, transform them and store the transformed resource into some persistence. The assumption is that each of the node is aware of the dependency template that is shown above.
Building the Solution with PROCESSING AND DEPENDENCY CLUSTER
Just to brief out the solution, when a node receives the resource, In addition to transforming the resource, it also generates other events which is handled by another cluster of nodes(dependency RESOLUTION nodes).These are the special cluster of nodes which handle the Dependency resolution.
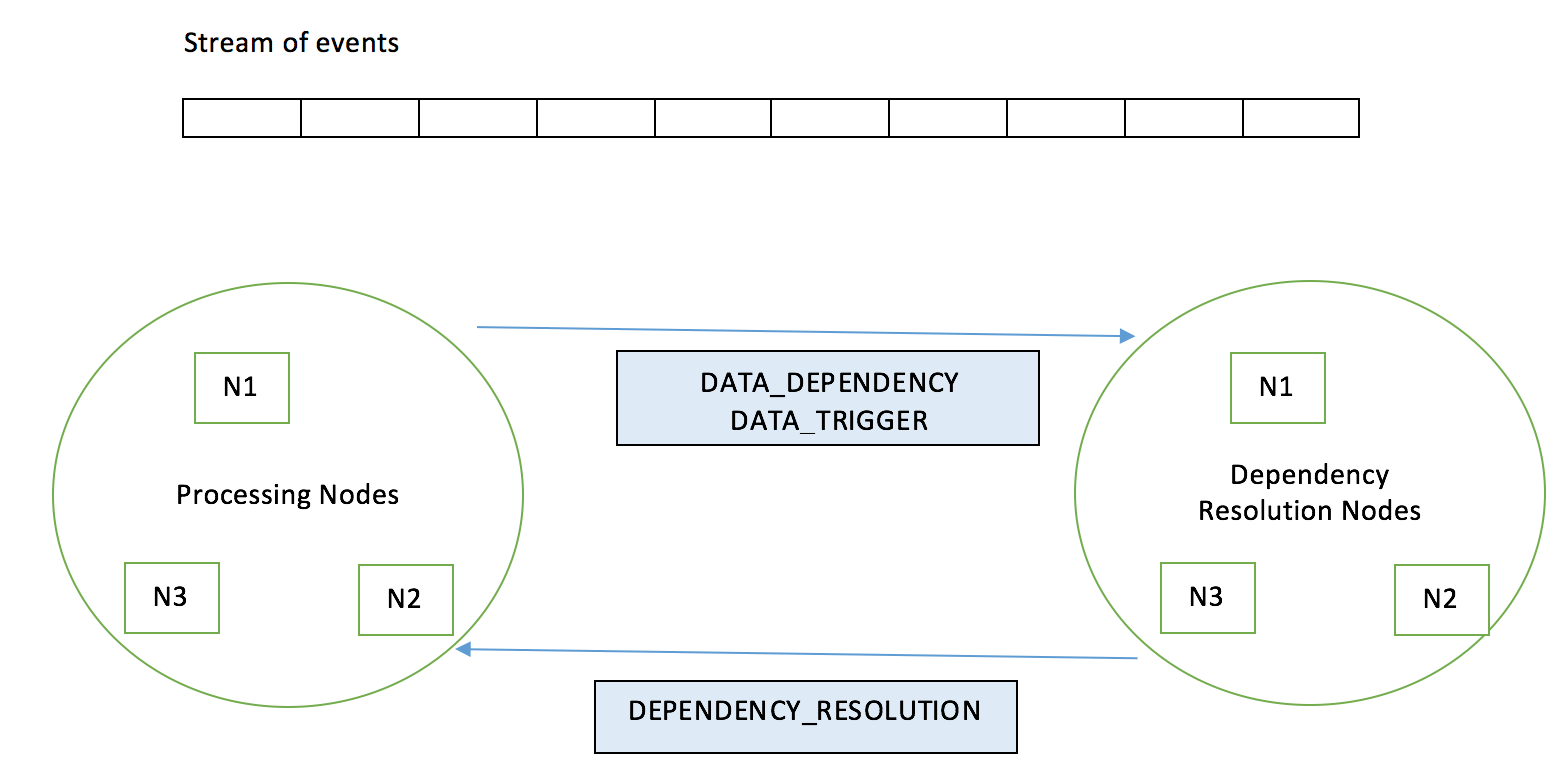
There are three main events that help in DDR.
DATA_DEPENDENCY, DATA_TRIGGER and DEPENDENCY_RESOLUTION
DATA_DEPENDENCY Event This event carries dependency information of a particular resource. eg: If R1 refers R2, Then the DATA_DEPENDENCY event carries the dependency information as dependant resource R1 and dependsOn R2. {dependant:R1,dependsOn:R2}
DATA_TRIGGER Event
This event carries the data arrival information which includes the details of the data.
eg:If R2 arrives the processing node sends a DATA_TRIGGER as below
{data:R2}
The question is who handles these (DATA_DEPENDENCY and DATA_TRIGGER) events.
There is another cluster of nodes called the dependency trackernodes.
Dependency TrackerNodes
When DATA_DEPENDENCY arrives it creates some sort of data structure to store the dependants and dependsOn information.Now when DATA_TRIGGER arrives the trackernode determines all those dependants and notifies the Processing Cluster with DEPENDENCY_RESOLUTION event for each dependants of the arrived data.
DEPENDENCY_RESOLUTION
This event carries the information of the data dependants whose dependency got resolved.
eg: When DATA_TRIGGER of R2 arrives, a new DEPENDENCY_RESOLUTION event is sent which includes the dependent information of R2.
{dependent:R1,dependentData:R2,roots:[R1]}
Note the roots fields.This field carries all the root nodes which are affected as a result of this dependency resolution.In this case it is only one root R1.If there was another resource which was dependent on R2 then root would have that resource Id as well.
Lets take an example.
We have bunch of resources as illustrated above.Note that each of the resource arrive independently and a resource refers another resource byId.
Lets say the queue has the resources in the following order.

Note that there are 3 nodes in each cluster which means that atleast three events can be processed concurrently as depicted below.
R1, R2 and R11 are picked up by the Processing Nodes in the first cycle.
When R1 is processed, DD1 and DT1 events are sent.
Similarly for R2 ,DD2 and DT2 events are sent.
The process is repeated for all the resources in queue for R11 , R4 , R5 and R3 during the sub sequent cycles.
On the other hand Data Dependency/Data Trigger events of R1 i.e. DT1, DD1 are processed by the Dependency resolution Nodes.
When DT2 is received which is the data trigger for R2,all the dependents of R2 are evaluated (currently R1) and DR2 (Dependency resolution for R2 {dependent:R1,dependentData:R2,roots:[R1]}) is generated.
Similarly for other resources R4,R5 corresponding Dependency resolution events DR4,DR5 are generated.
Note for R3 the DR3 will looks as follows. {dependent:R2,dependentData:R2,roots:[R1,R11]}
When DR2 {dependent:R1,dependentData:R2,roots:[R1]} is received by the Processing Nodes, It updates the R1 graph with R2 information.Similarly when DR4,DR5 and DR3 are received R1 and R11 graphs are updated with R4,R5 and R3 information.
Edge Cases in DDR
When we closely look into the above example, during the first cycle when R1 R2 and R11 are taken for processing, if R2 is not persisted while R11 is getting processed then R11 graph is never updated with R2 information since R2 DEPENDENCY_RESOLUTION would have been already done. One way to solve this is every time DATA_DEPENDENCY event is received, check if the required data is available and send DEPENDENCY_RESOLUTION event for that resource.
Scalability,robustness and consistency of the DDR
DDR is a completely auto scalable solution. Adding/Removing nodes to either of the cluster will not affect the robustness and consistency of the system making it truely scalable.