Gluing the Sliced/Diced Metadata in a Distributed way
Problem Description
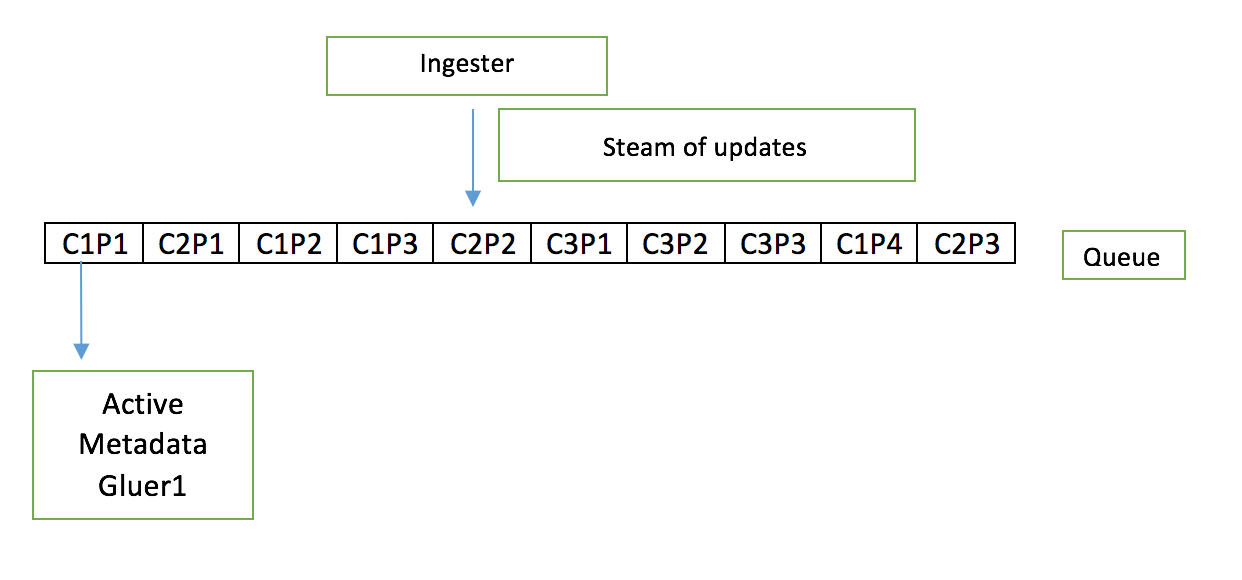
The Metadata Gluer is responsible of Glueing metadata of content/contents from multiple sources. The content metadata can arrive in many pieces and the metadata aggregator is responsible of glueing these pieces. For example lets say we have a content C1 in XML/Json, and its metadata arrives in many pieces C1P1(content1Piece1),C1P2 … over a discrete interval of time(not necessarily continious).For simplicity lets assume there is a queue for queung all these piece by piece updates ‘Cnpn’.And each of the piece can insert/update/delete different parts of the content XML/JSON.Note that the final metadata of content must be consistent. Also note that as and when pieces are glued, the current state of content is sent as an update for downstream components which process this update to the content.
Challenge
The challenge here is to build an active-active solution where there are multiple instances of Metadata Gluer running concurrently.This is extremely important since the data load can be too high specially in a multi tenant deployment and the granularity of the pieces are small and frequent.
Solution1: Active-Passive
Before we get into the active-active solution, lets try to understand the Active-Passive solution.There is one Metadata gluer instance which processes each pieces one after the other for all contents and glues each piece update one after the other and notifies the downstream components. If the active instance goes down there is a passive instance which can takeover from active and continue.
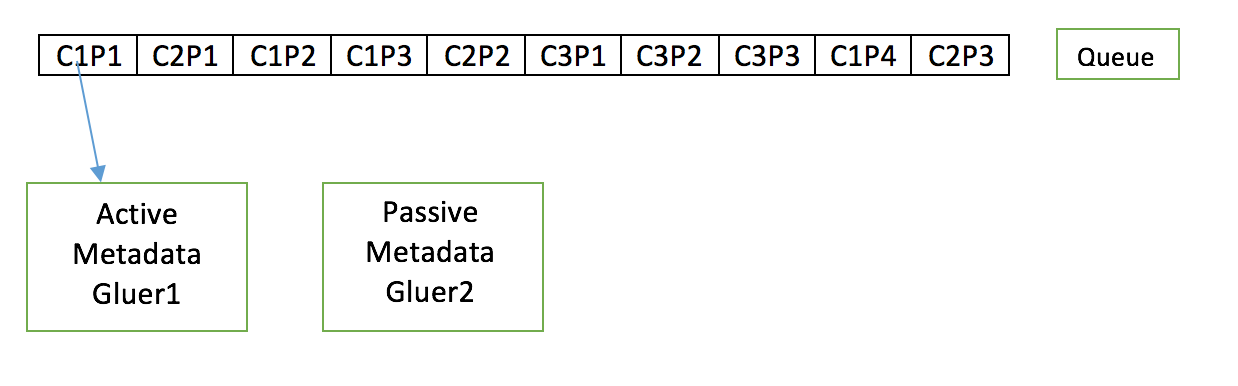
Pros and Cons Pros
1. Easy Deployment Model
2. Very Simple implementation.All the Gluer has to do is join pieces as they arrive.
3. Suitabe when the updates are infrequent and data load is less.Cons
1. Does not scale with data load.
2. Multi tenancy will require separate instances of gluer for each tenant. Even then it might not scale with higher data load per tenant.
3. Costlier deployment if the number of tenants are more.
4. Higher Maintainance iwth large number of deployments
5. Not suitable for SAAS kind of model
6. The granular updates (C1P1...CnPn) are queued for long time since there is only a single instance processing these updates.Hence downstream components receive the updates very slowly.As a result takes larger time for update propogation downstream.That brings us to the active active solution which addresses all these concerns.
Solution2: Active-Active (Distributed Glueing)
There are multiple instances of metadata gluer processing the updates concurrently.As and when the updates arrive they are picked up by the free active instance and starts processing.
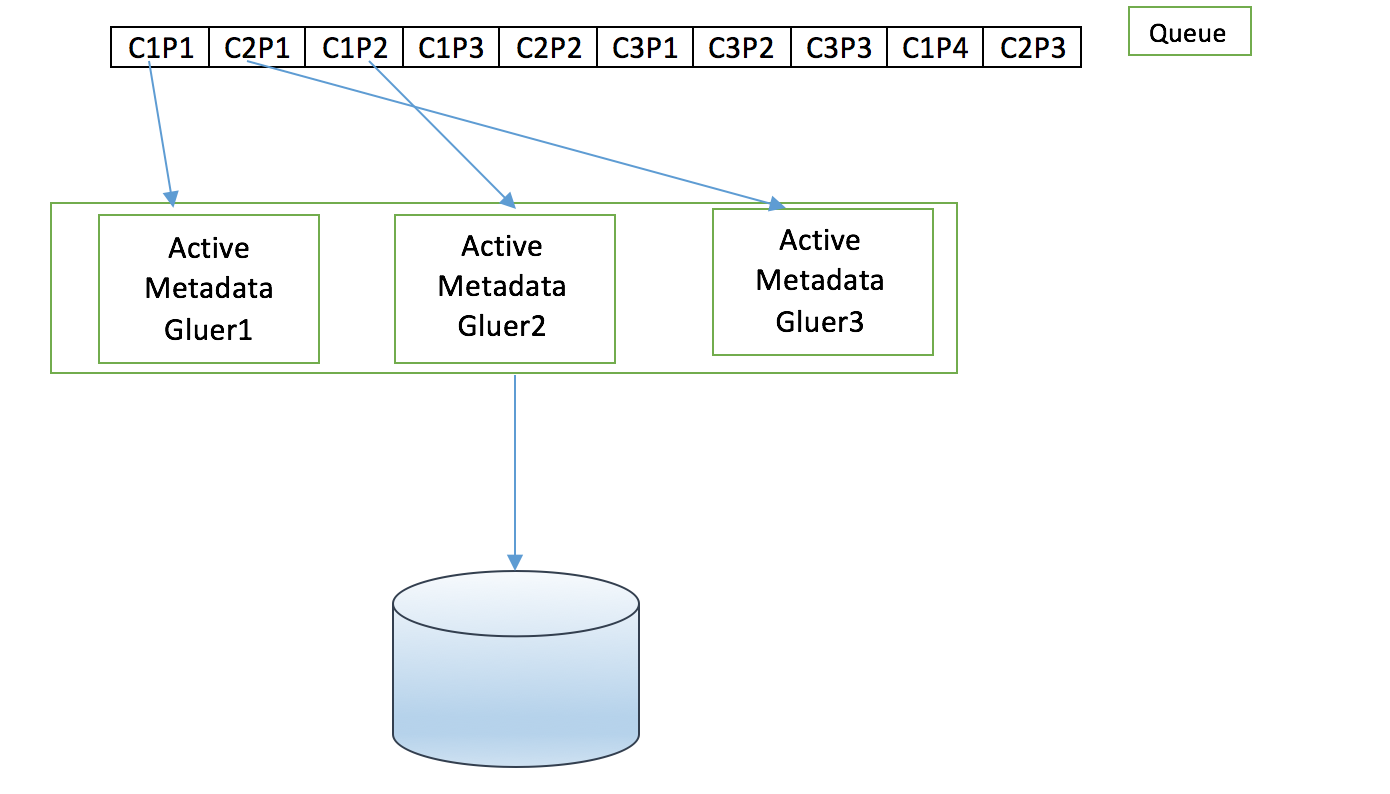
Just adding multiple instances will not solve the problem since there is a constraint that the updates(C1P1,C1P2,C1P3…C1Pn) of a particular content (C1) has to be processed in order and the final state of content (C1) has to be consistent. The above architecture will not address this constraint since there is a possibilitily that updates C1P1,C1P2…C1Pn can be adjacent in the queue and multiple gluer instances can take these updates simultaneously.As a result the final state of the content (C1) might be inconsistent
To address this challenge lets tweak the above architecture and make it flexible enough to address the above issue.Lets have a separate queue for each metadata gluer instance as shown below.
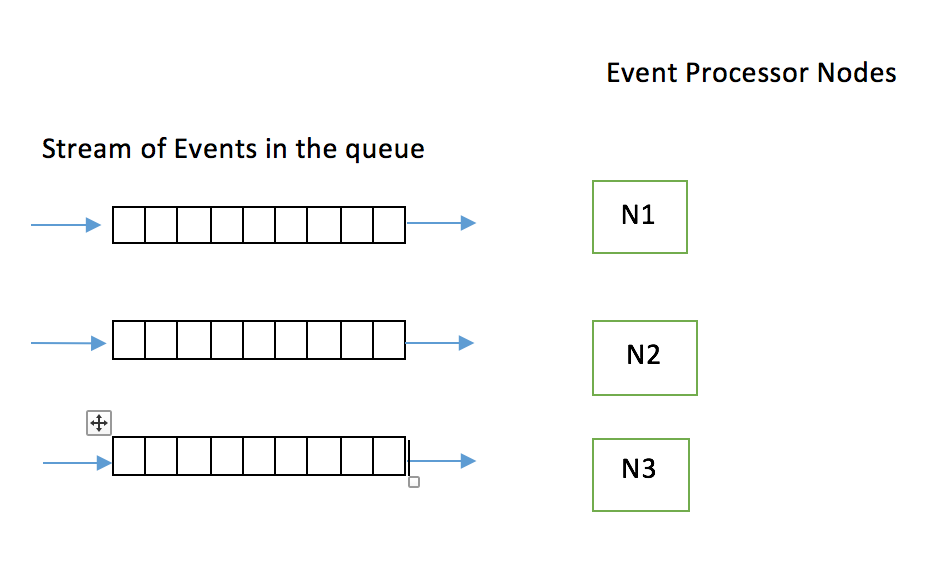
The queue creation and events forwarding to each queue is taken care by many message bus technologies like RMQ,KAFKA. So the queue management responsibility is offloaded to Message bus.
Here comes the Hash trick
Many distributed persistent technologies like cassandra,couchbase,mongo rely on hash based partitioning for data distribution across nodes.The same technique can be used here for load distribution across gluer instances.Each node is responsible for glueing the content for a range of hash values.
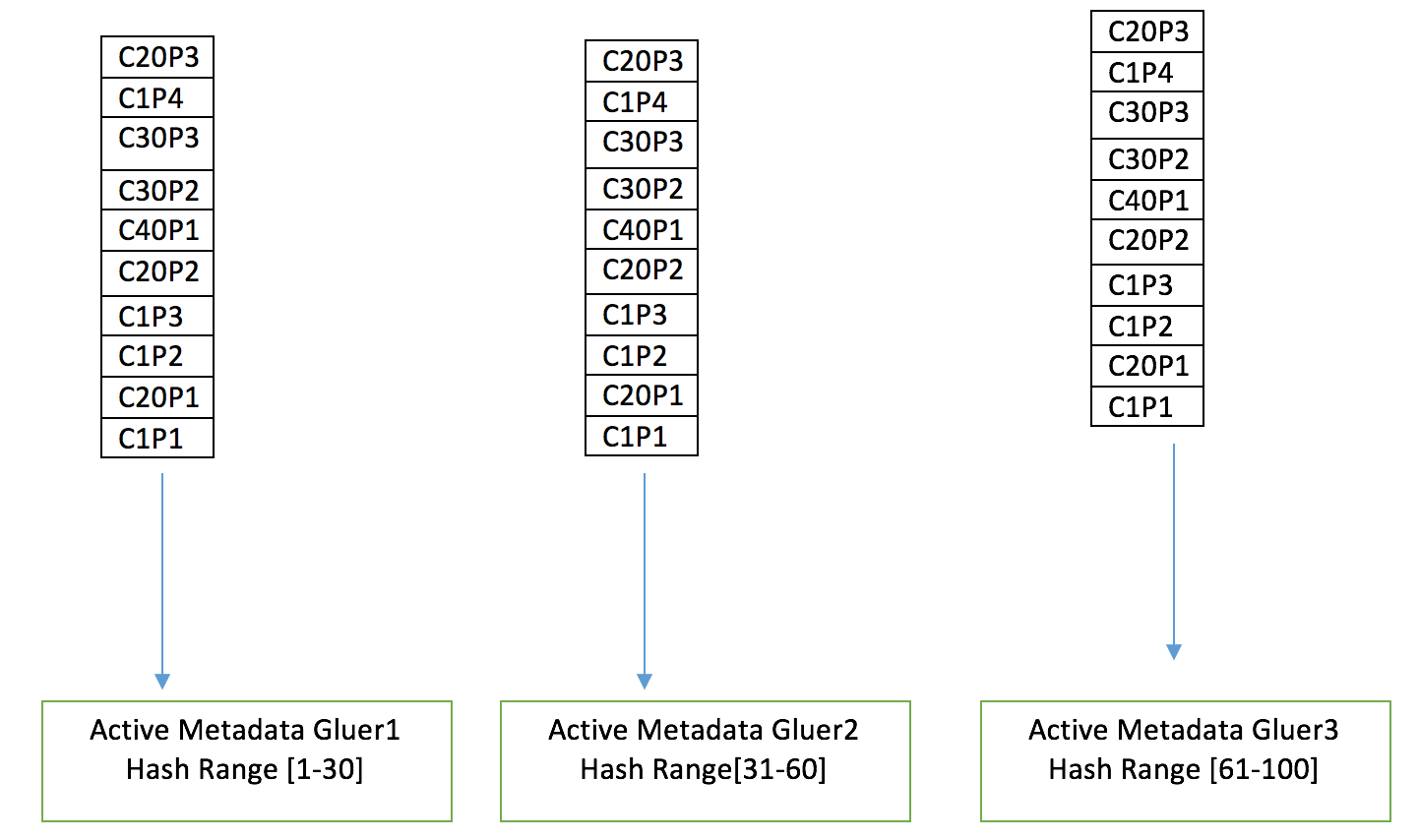
For instance in the above example lets say gluer1 has a hash range of 1-30,gluer2 has 31-60 and gluer3 has 61-99. Since all of them have a mirror of update events, each of the gluer filters the events based on the above hash range. Gluer1 only process contents 1-30 and rejects all events that are outside its range. Therefore the Gluer1 process the updates(C1P1,C1P2,C1P3…C1Pn) in order there by ensuring the consistentcy of the contents.
Note that the load is shared among the nodes yet ensuring the consistency.
Gluer1 Flow of events
C1P1 : C1 is in the hash range, processes the C1P1 event and glues the update in C1.
C20P1 : C20 is in the hash range, processes the C20P1 event and glues the update in C20.
C1P2 : C1 is in the hash range, processes the C1P2 event and glues the update in C1.
C1P3 : C1 is in the hash range, processes the C1P3 event and glues the update in C1.
[Note the updates C1P3 is applied only after C1P2 making sure that C1 is in consitent state]
C20P2 : C20 is in the hash range, processes the C20P2 event and glues the update in C20.
C40P1 : C40 is in not the hash range, Drops this event.[This will be processed by any one of the other gluer instances]
C30P2 : C30 is in the hash range, processes the C30P2 event and glues the update in C30.
C30P3 : C30 is in the hash range, processes the C30P3 event and glues the update in C30.
C1P4 : C1 is in the hash range, processes the C1P4 event and glues the update in C1.
C20P3 : C20 is in the hash range, processes the C20P3 event and glues the update in C20.Similarly all the other instances filters the events based on their hash range and process the events.
Lets work out the details.
Establishing communication among the Nodes
One of the key requirement of any distributed technology is to have some sort of communication among the nodes for knowing each other and also for exchanging some information among themselves to co-ordinate.There are many ways of achieving this.Example Gossip Protocol used in cassandra which is fairly extensive and complicated one which is not required in our case.One Simple way is by using a centralised persistance to which all the nodes have access to and each node updating its information in that persistance.
Adding a new Node to the cluster or When a node dies in the cluster
There are many approaches that can be used.One of the simple approach is to assign the nodes a sequence number as they are added as shown below.
Current state of Gluer Cluster
GluerInstanceId NodeId
Gluer-1782 1
Gluer-1572 2
Gluer-1682 3
Add a new Node Gluer-1192
Gluer-1192 4
Note the Gluer "instanceId" doesn't matter, it can be anything. But the sequence number matters.The sequence number can also indicate the nodes slot in the cluster.The new node can compute the sequence number by itself by refering the current state of cluster in the centralised persistence.
When the node dies in the middle of processing,all the resources that fall under the hash range of this node will not be processed untill the node comes back. When the node comes back or a new node is added[which is the same], while selecting the sequence number it should select the empty slot and resume processing the resources from that queue.
Queue Creation
Once the node determine its nodeID , It checks if the queue with name NodeId exists. If it exists it attachs to that queue and starts processing.If not it creates a new queue with name NodeID.
So far so good. But still it doesn’t fly. We need to figure out the following.
How can the nodes determine the hashrange themselves?
How can nodes update their hashrange when new nodes are added/deleted?
How do we handle the failure of nodes?
How do we scale based on load?
Isn't this over engineering?How can the nodes determine the hashrange themselves?
Assuming that the nodes have determine their IDs ,when the events arrive in the queue. they can determine if that event needs to be processed or not themselves by a simple math as given below.
Long hash = (long) Math.abs(eventId.hashCode());//Compute the HashCode of the eventId
int nodeId = (((int) (Math.abs(hash) % totalNodes)) + 1);//Get the nodeId using a simple modulo function
if(nodeId == itsNodeId)
then process
else reject
end ifNote in the previous discussion we had assigned contiious hash range (1-30,31-60). But the above method is a much better alternative which distributes the load well.
How can nodes update their hashrange when new nodes are added/deleted? or How do we scale based on load?
It might be required to add new nodes to cluster when there is load in the system.However the above method cannot scale up/down in accordance to the load.It is still an active-active solution but it doesn’t scale up/down.:(
Adding a new node to the cluster during high load is also carrying a subtle side effect. According to the Hashing approach, when a new node is added all the nodes recompute their hashrange. If you think for a minute and workout, we can clearly spot a problem. Since the hashrange has changed, all the nodes start dropping the resources that belong to the new node [i.e. the nodes start droping the resources which are not in their range which might have been in their range before]. As a result all the updates of resources falling under the new node are lost. A new node has to be added only when all the queues are empty. Clearly this is not auto scalable since we would like to add a new node when there is lot of load in the system and not when there is no load.[Note : Work in progress to figure out a way of auto scaling.]
How do we handle the failure of nodes?
The failure of nodes is still handled with the above approach.If a node fails, then all the updates of contents that fall in its hash range are not propogated.But when the node comes back/new node is added(which is the same) , takes the sequence number of the previously died node, and hence can start processing the events just like before.
Well the most important question…..
Isn’t this over engineering?
Well that is subjective. If something is engineered for the sake of it and it doesnt serve any purpose, then it is over engineering.But If something is done to solve a pertinent problem then coining it as over enginnering is incorrect.Also most of the approach taken above is very simple to serve the required purpose.The right questing to ask is “Is it required?”. That brings us to the following section.
Pros and Cons
Pros
1. Handles large data loads
2. Suitable for multi tenant deployment
3. Updates are propogated to downstream components faster.
4. No separate deployment needed for each tenant
5. Suitable for SAAS kind of modelCons
1. Additional infra like messsage bus is needed.
2. Complexity in handling aspects like node discovery,hash range distribution, failure handling.
3. Not Auto Scalable :( which is a big downside. It is required to precalculate maximum load and decide the number of instances.We analyzed the pros and cons of Active/Passive and Active/Active approach of solving the gluing of content metadata.The Active/Passive does solve the problem in a simple way but it clearly doesn’t handle large data load.If there is a need to support multitenancy where the data load will be higher active/active approach is the way. But it comes with its own baggage. The decision clearly depends on the requirement.