Dissecting the RNN[Recurrent Neural Network]
RNN
Regular Neural Networks perform exceptionally well in understanding complex non linear data.There are certain requirements for a different class of applications where it is necessary to keep track of past information. For instance Image captioning, Language translation, Language modelling, Sentiment analysis, Video processing and other similar use cases. Regular neural networks lack the ability to capture past/sequence information from data. RNNs are built to solve this exact problem. RNNs have the ability to understand sequences in data and predict based on current input plus the previous state.
Refer the following blogs on RNNs to get an in depth understanding of RNNs in simple words.
The Unreasonable Effectiveness of Recurrent Neural Networks by Andrej Karpathy
Understanding LSTM Networks
Note: The remainder section assumes that you have a basic understanding of RNNs
Its OK if you are in the Stage2.
You flow through different stages of emotions while working with RNNs.
Stage1: WOW!! RNNs are so cool...
Stage2: WTF!! How does this work?
Stage3: Aha!! Damn!! I knew it..I personally spent a lot of time in Stage2 trying to get the intuition of WTF is happing inside the network that it is able to understand sequences in data. But once you get that aha!! moment you will realise how simple RNNs are. In fact the simple RNNs(Vanilla RNNs) are very similar to the vanilla neural networks except that the hidden states are computed in a different way. The hidden state function is what gives the RNN the ability to store previous states information and use it along with the current state to predict output.
Questions that haunted me:
How does the gradients flow backwards through time?
How are the weights updated backwards through time?
What information should be maintained while propagating forward through time?
What information should be maintained while propagating backwards through time?I found answers to all these questions once I started writing computations graph through time during forward propagation and then did a backward propagation backwards through time.
Dissecting the Recurrent Neural Network
For the sake of example lets consider 3:1:1 neural structure with i/p,hidden and o/p respectively. We will use sigmoid as activation functions in hidden units and output layer. Lets set the sequence length to 2.
During forward propagation we iterate through the input for the sequence length(2 in this case).
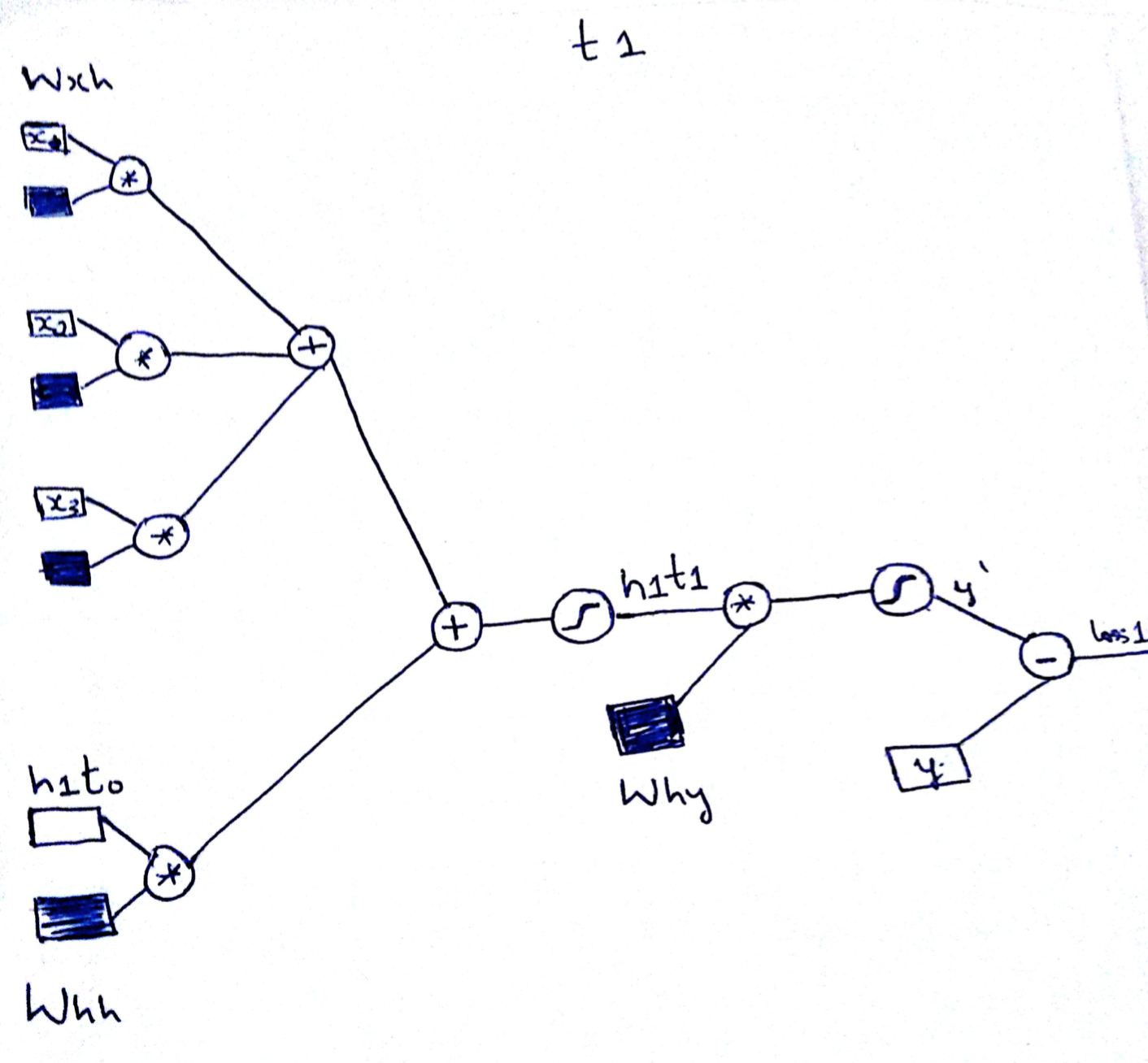
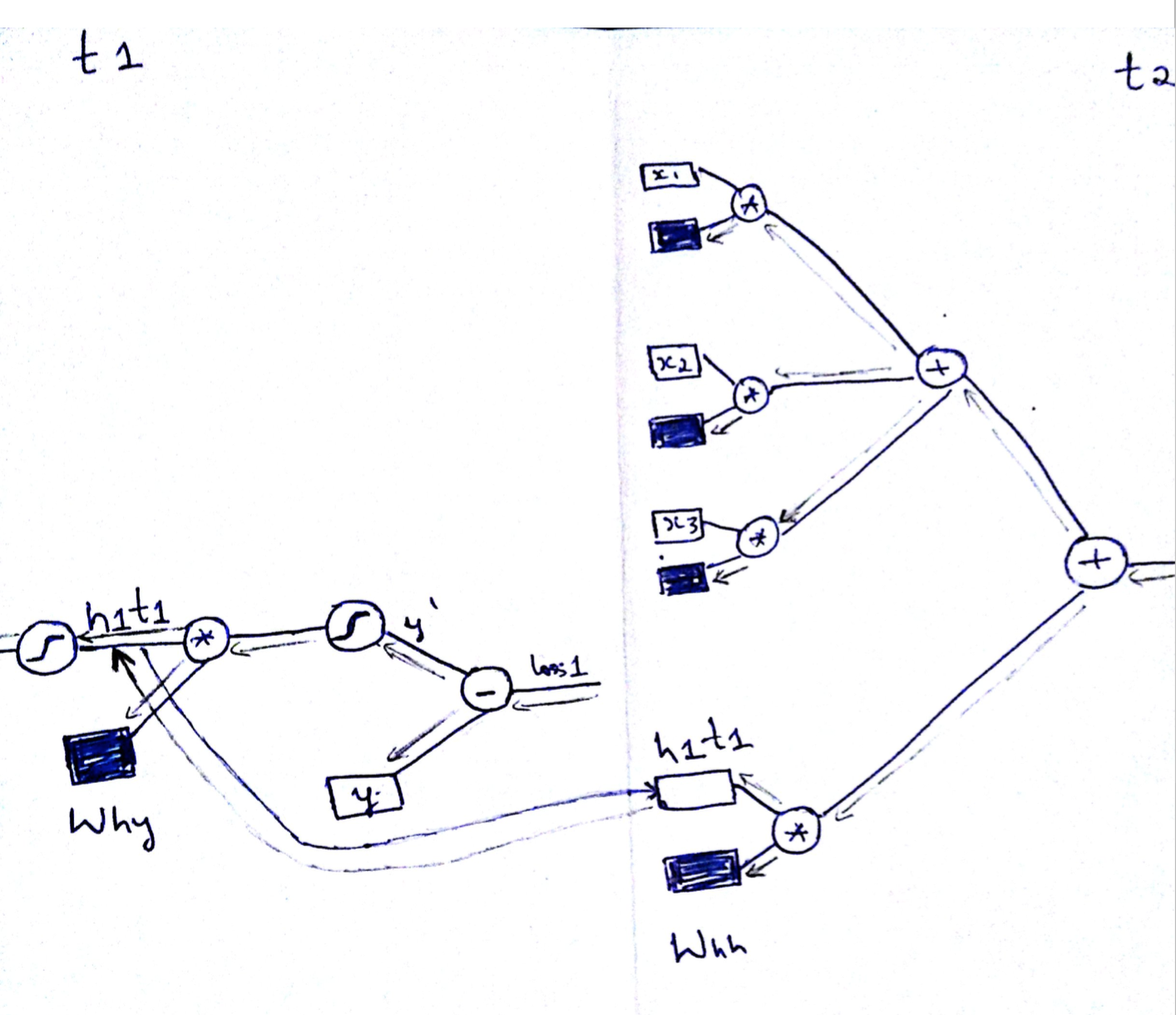
Forward Propagation in RNN at time t1 is as illustrated below.
h1t1 = sig((Wxh . X11) + (Whh . h1t0))
y' = sig (Why . h1t1)Note: h1t1 denotes the hiddenstate h1 @ time t1.X11 denotes the 1st input of 1st sequence
It is important to notice that the hidden state is a function of input as well as the previous state.h1t0 can be chosen as ‘0’ to start with.
h1t1 = sig((Wxh . X11) + (Whh . h1t0)).
Similarly Forward Propagation in RNN at time t2 is as illustrated below.
One important thing to notice here is that same weights are used during all the time sequence but with different input from the sequence. In this case X12.
Note: h1t2 denotes the hiddenstate h1 @ time t2.X12 denotes the 2nt input of 1st sequence
h1t2 = sig((Wxh . X12) + (Whh . h1t1))
y' = sig (Why . h1t2)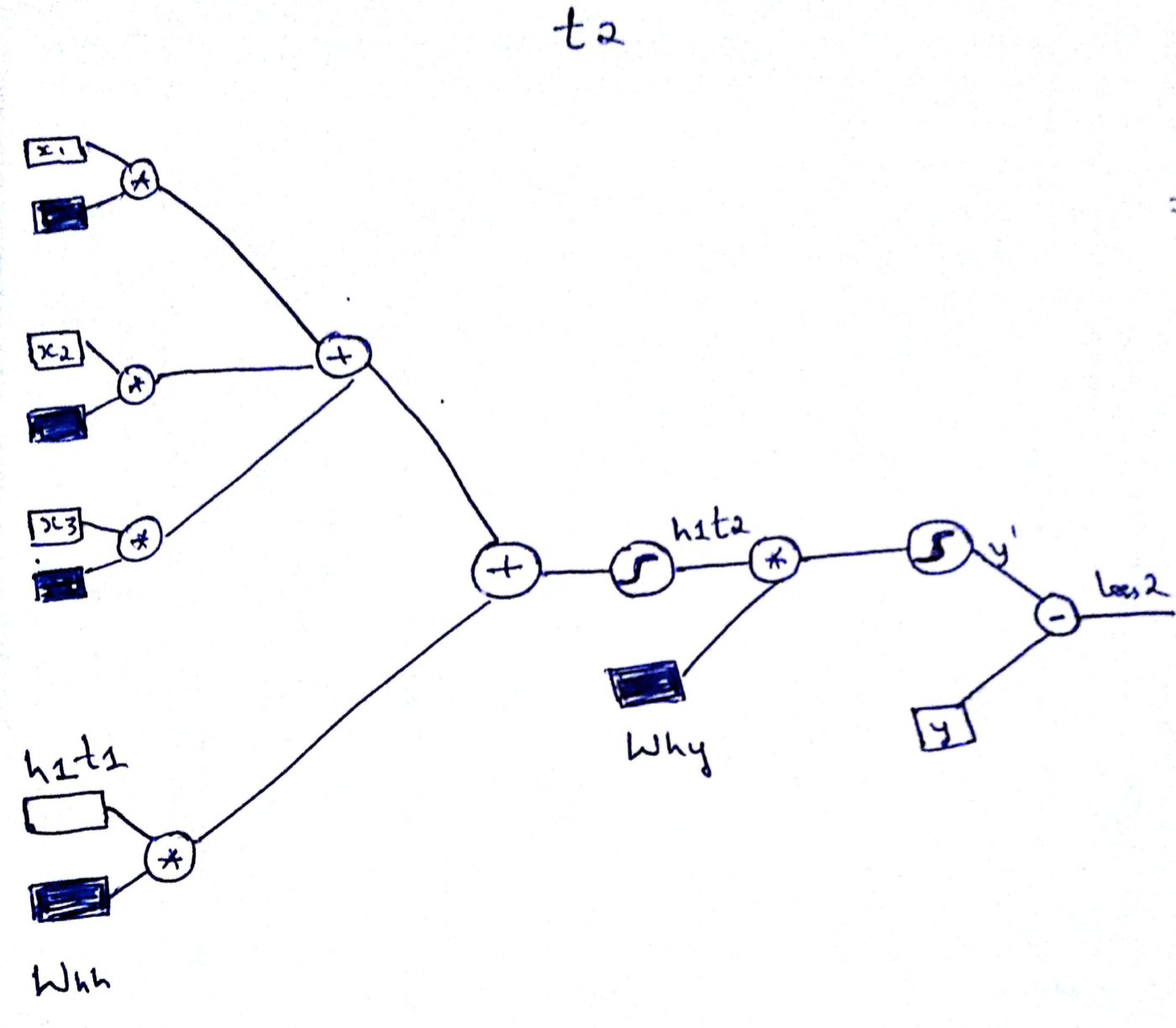
Now lets look at the backward propagation. As I said we do backprop backwards through time form t2->t1 as shown below. BackProp is very similar to the vanilla neural nets.Not much of a difference.
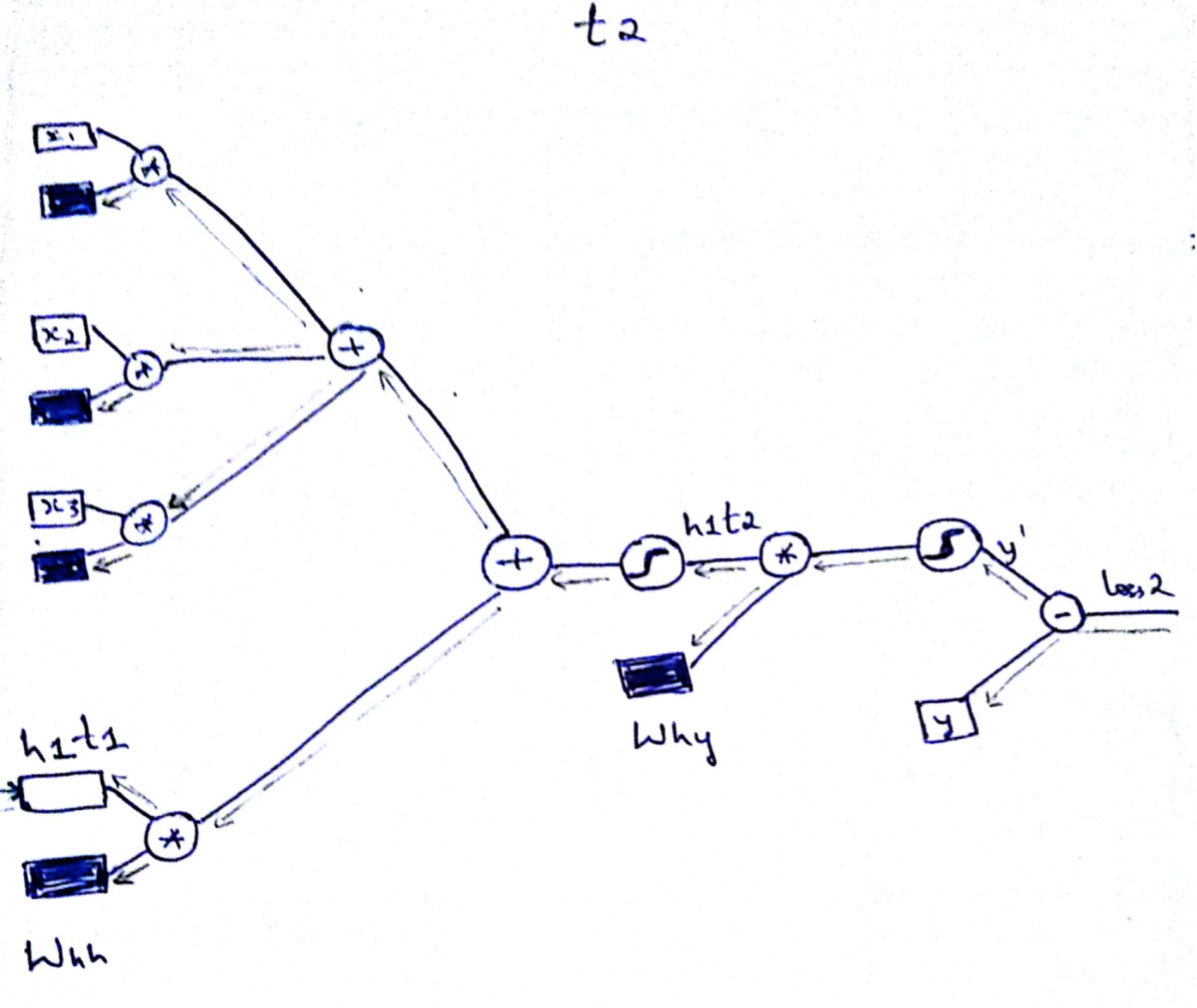
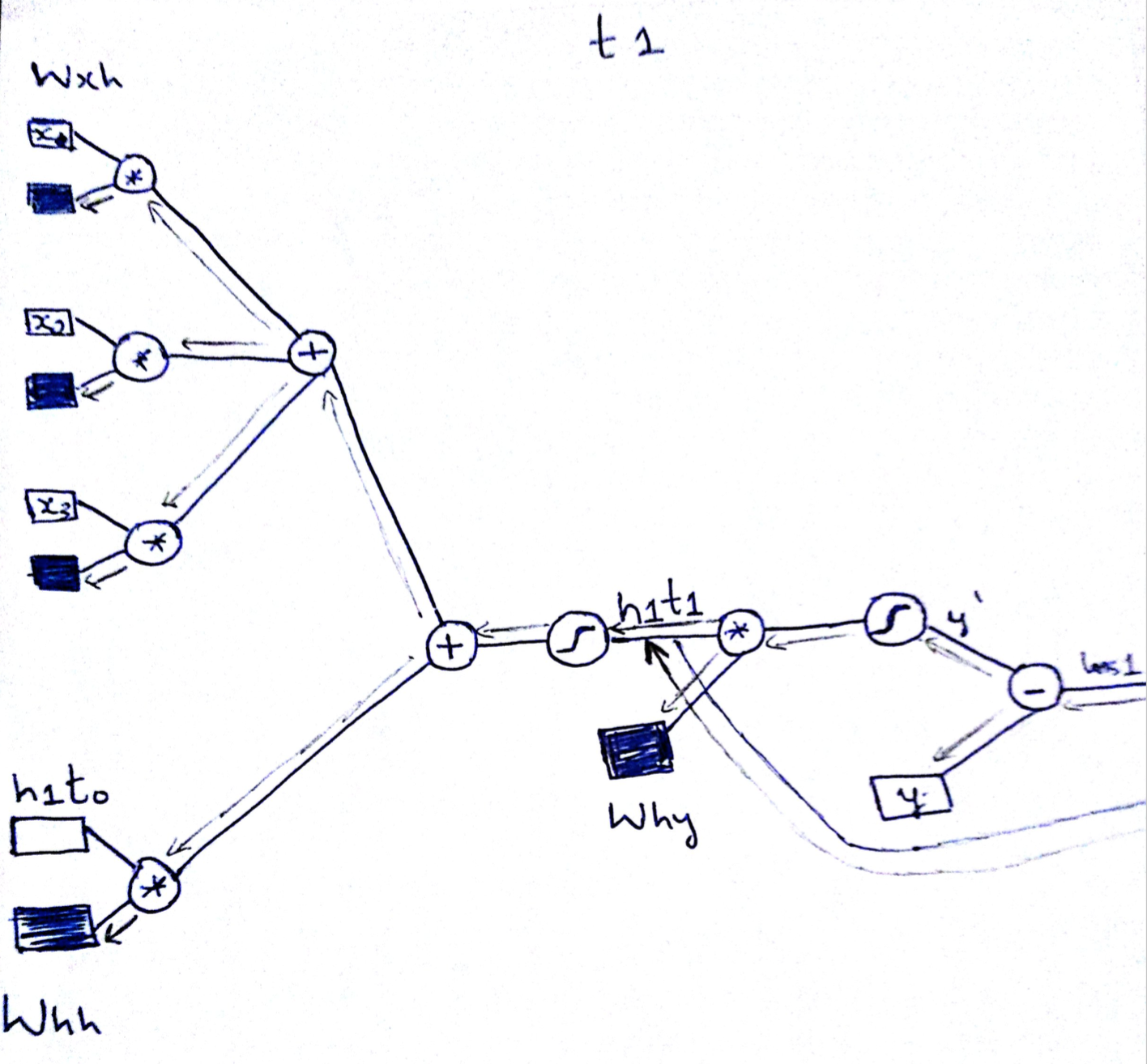
The most important and subtle thing to notice here is the way back prop is done across different time sequence. Since the hidden state is a function of its previous state, while back propagation, we need to take into account the gradient flowing backwards through time as shown below. Every time step we update the weights and also save the gradient of the hidden state at that time step(say t2) and propagate the gradients to previous time step(t1).
Vanilla Neural Network vs Recurrent Neural Network
The main difference between the VNN and RNN is the way the hidden state is computed. The above RNN can be converted to VNN by removing the sequence and cropping some part of the RNN as shown below.
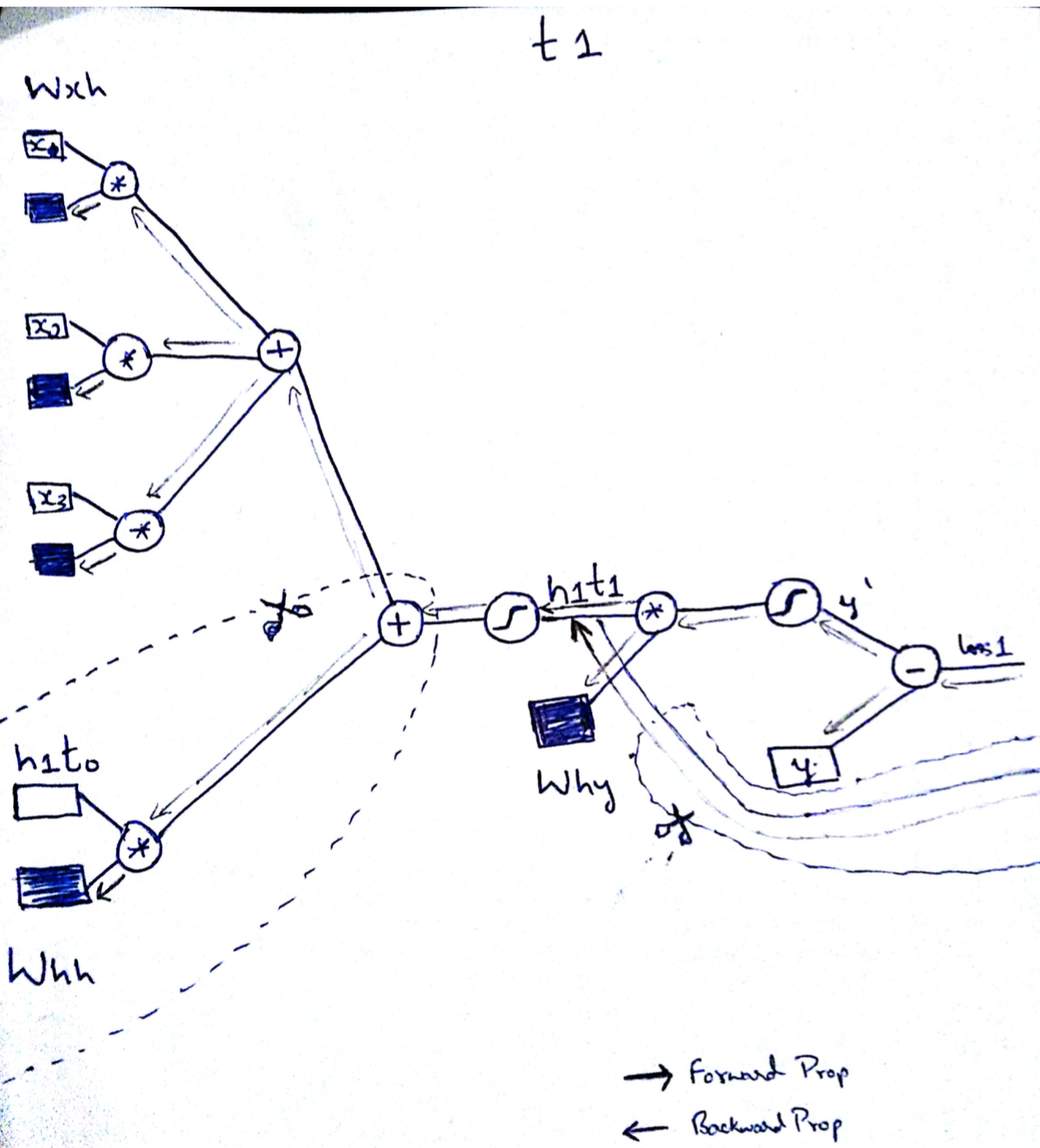
Sorry about the handwritten diagrams.I hope you get some intuition as to how weights in RNN are getting tuned backwards through time to understand sequence in data. I insist working out the derivatives of the above network to better undertand the flow of gradients through time.Also you might have noticed we need to keep quite a lot of information in memory during forward and backward propagation in RNN based on the sequence length.