Design for Resiliency, durability, Failure Recovery and Idempotency
Flow with the Chaos
In Distributed systems we cannot avoid chaos and definitely not assume that there wont be one. We have to code for the chaos and manage the chaos.
Why Resiliency, Durability and Failure Recovery is required
Lets take an example of addProduct in ECOS-[Enterprise Customer Order Service].The responsibility of this service is to take orders. Lets say the sequence of step involved in ECOS is as follows for adding the product in the order.
- Receive the request
- Check restrictions on the given product with restriction service
- Add the product to the quote service
- Add the product to the order and persist in some data store along with the quote
- Publish a business event for the added product
All the sequence has to be executed completely or not executed at all. Following are the reasons why partial execution of the above steps would have adverse effect in the system.
For instance, in addproduct,
- The product is added to quote
- The ECOS instance failed Note: The product is not added to the order and also the event is not published, however the quote is updated in price.
- On Failure,The client again sends the request again, we end up adding the same product again into the quote and then we add it to order and send event.
As a result of this We have added the product twice in quote and once in the basket.
Similar kind of situation can occur in many ECOS use cases. So it is extremely important to ensure we have strong failure recovery mechanism built in ECOS without compromising Scalability and idempotency.
Lets formalise the above problem in a general sense.
Formalising the problem statement:
We have a sequence of operations to be done for a particular use case. Related operations in this sequence can be grouped together into smaller sub-sets called Micro Modules.
For example price/quote related operations can be embedded in a single micro module(Price micro module). So this micro module is responsible for catering to all price related operations.Similarly we can have many such micro-modules.

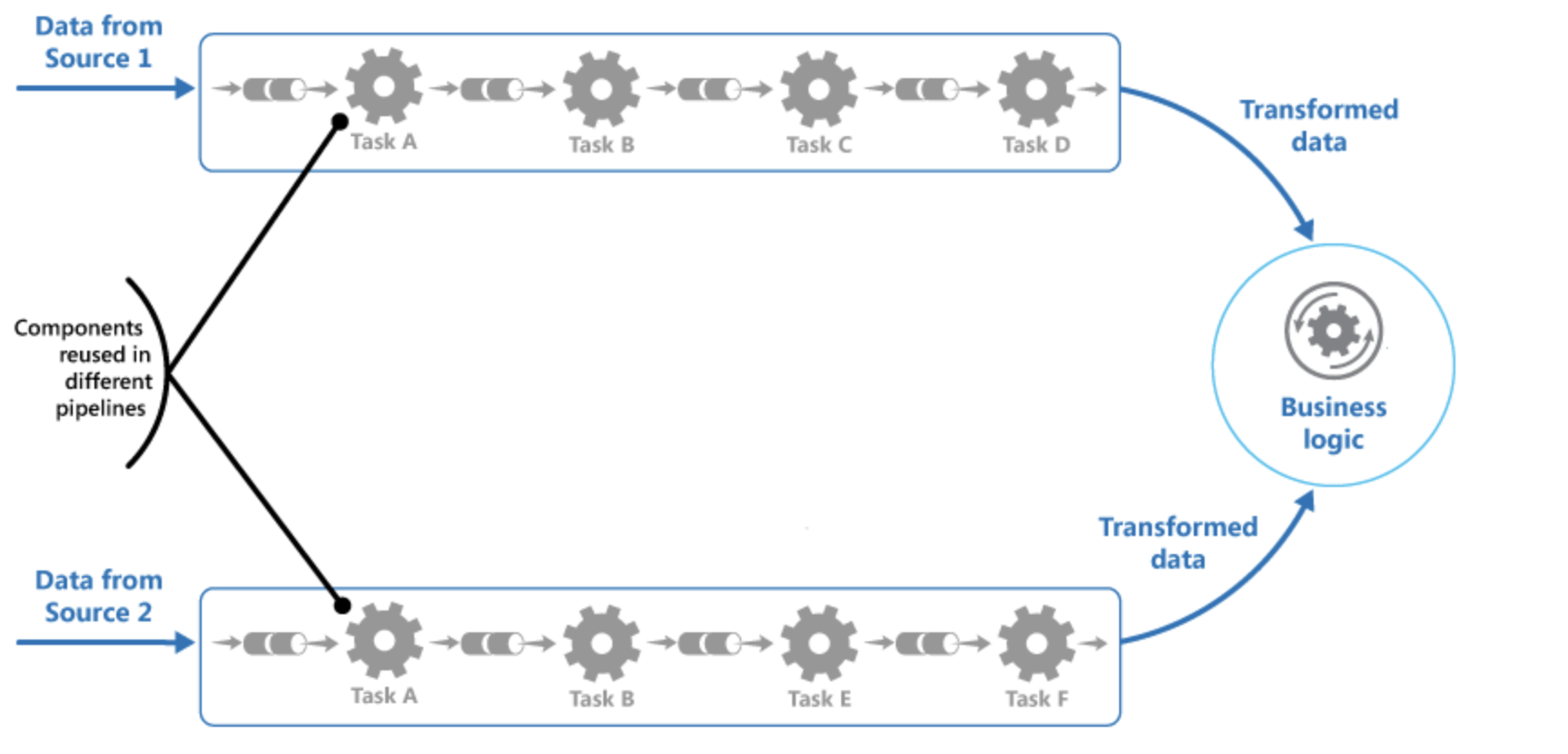
Monolith vs Pipies and Filters
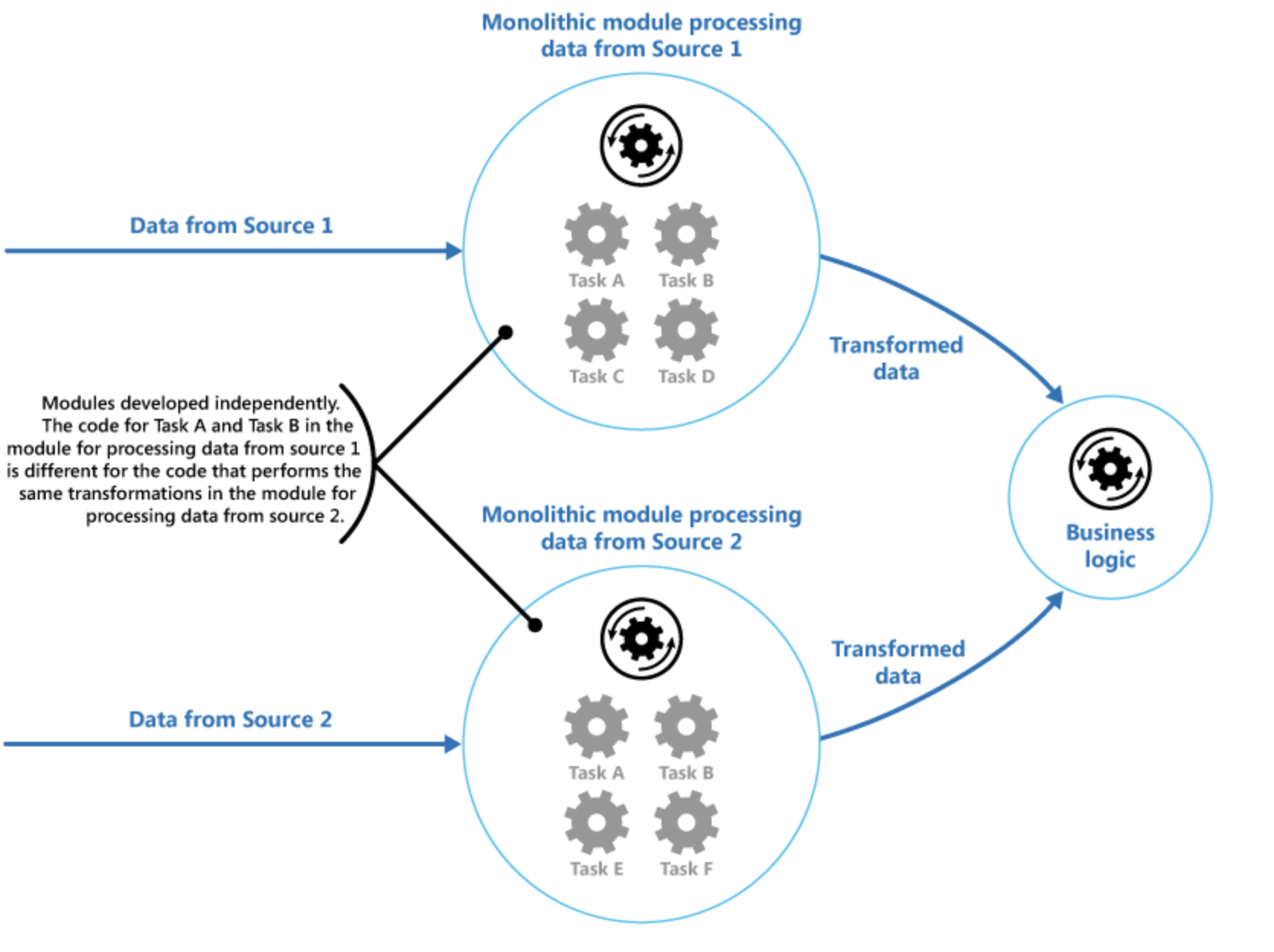
Reusing Filters across multiple services in Pipes Design.
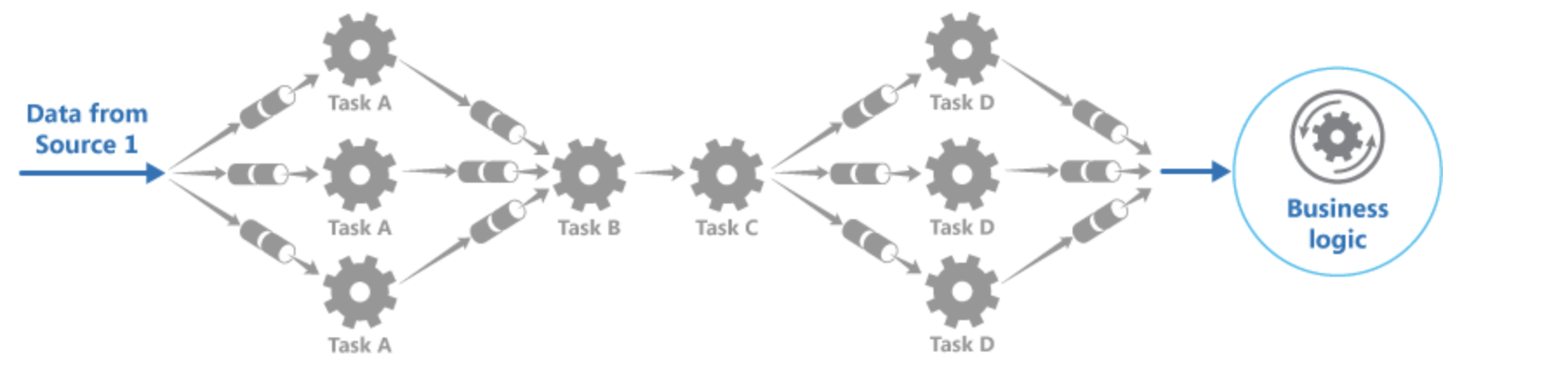
Each of the micro modules can be scaled independently. If a micro module is taking a long time more workers can be put in that micro module to increase the throughput and reduce the latency.
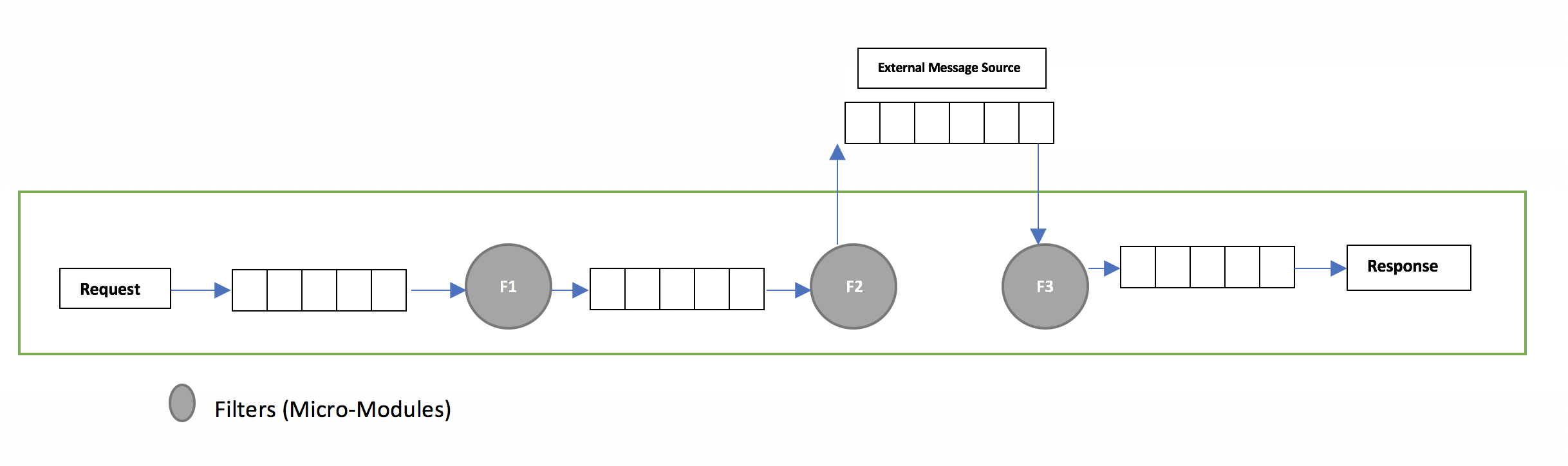
External sourcing of events
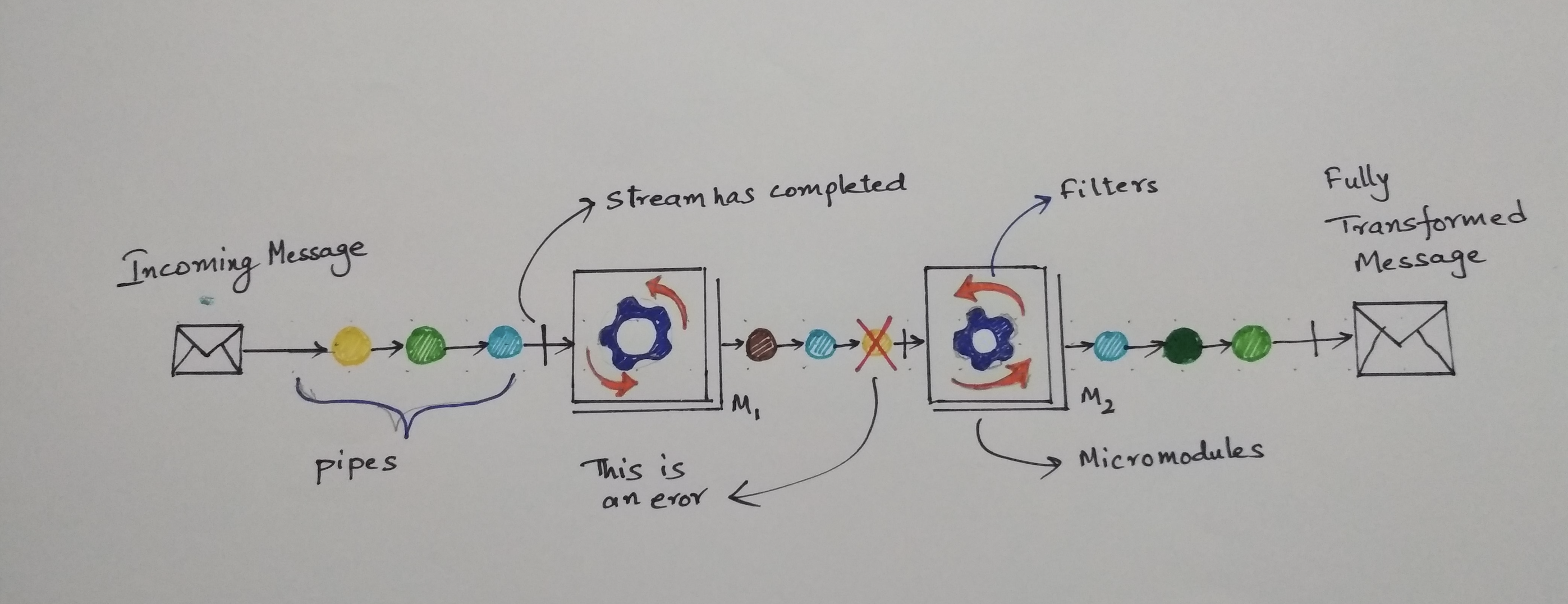
Each of the micro-modules work in isolation without depending on each other.The linking of these micro-modules results in achieving a particular use-case for ECOS.One way to link all these micro-modules is by using reactive pipe lines. As a micro-module, It is only interested in a particular stream of events. It does not matter if the stream originated from another micro-module or it originated from an external source. The following diagram illustrates streams originating from different kind of sources.
Challenges by piping Micro-Modules in ECOS
Errors and Failures in Pipes and Filters
Its important to note that error and failures are different. Errors are always within the context of the application. Failures are always external to application. For instance, Abrupt Failure of a pod in which the application is running is a “Failure”. Errors are internal application exceptions. Both errors and failures can create anamolies if not handled properly.
Handling Errors
The following depicts the application errors.
The main challenge here is to ensure that the errors are detected and contained and suitable measures are taken to ensure that state of the system is not corrupted.
For example in addProduct case, If there is some sort of an error after the quote is created, The errors streams down to the subscriber in reactive pipeline, Before responding back to the client, proper measures have to be taken to ensure the products are removed from the quote and system is left in a consistent state.
Handling Failures and ensuring commitment to the request
One of the challenges that needs to be addressed here is the failure of a micro-module while processing which can have an impact on the ECOS. For example if the pod dies due to resource constraint or the minion itself died.
Taking the add-product use case described before, If there is a failure after the product is added to the quote, the product might be added twice. Hence after certain operations we need some kind of commitment by ECOS that the operations following it will be executed no matter what
Critical Points in the system
Its important to figure out critical points in the system and take measures to ensure durability.
For example In the add product use case after the product is added in the quote, it has to be added in the order, persisted and a event has to be published before responding to the client.
Durability is the key aspect while designing a system which can update states across multiple sub-systems.Durability can be achieved in critical points in the system after which a commitment can be made that the sub-sequent micro-modules will be executed for sure.There are many ways to achieve durability.
-
Persistence : We can rely on persistence where we can save the intermediate state of the critical point and If there are failures we can always start from the last point where we left off for that request.
-
Durable Queue: Here we can save the intermediate state of the critical point as an event in a Messaging system and later consume that event and continue the remaining operations. An acknowledgement is sent only after the execution of all the remaining operations.
Scenario illustrating the failure and failure recovery using durable queue
Lets take the following example where the ECOS was able to add the product to the quote, then the intermediate state was persisted using a queue which is later picked by the add product micro-module to add the product to the order . Now Failure of the instance is as depicted below which causes the add-product micro-module to fail.
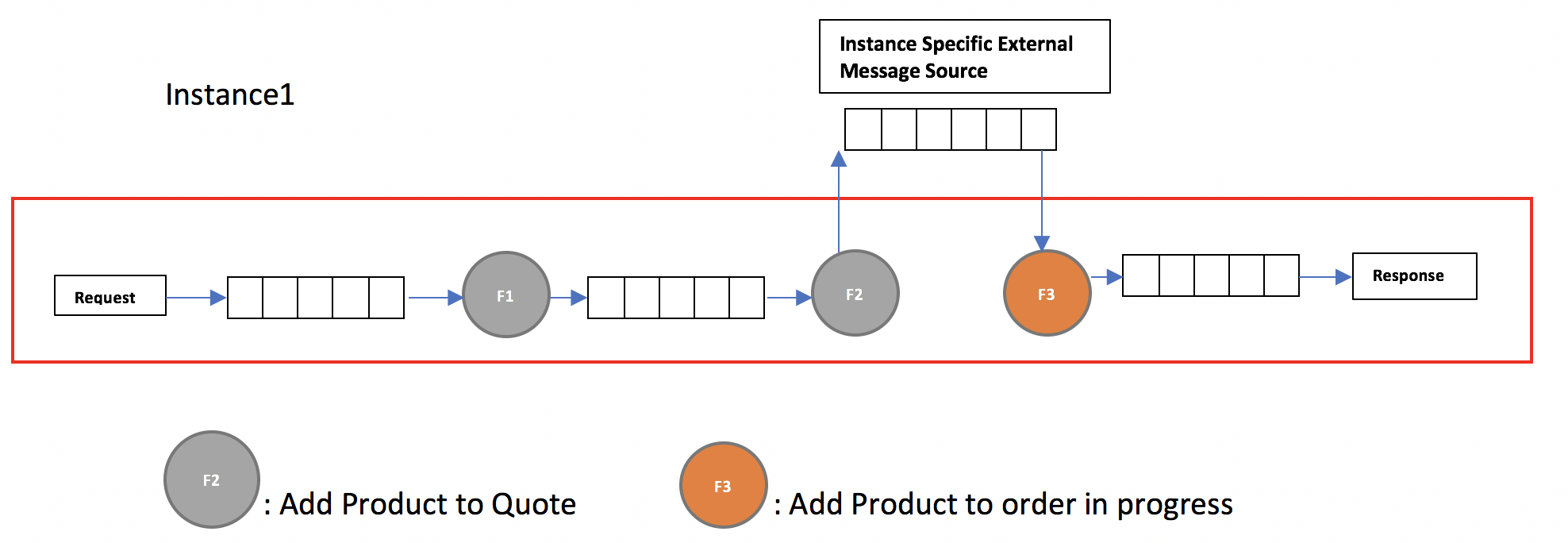
Failure Recovery is as illustrated below. Since the add-product did not send the acknowledgement the message was still not removed from the queue. Now when the instance comes back again ,the add-product micro-module will get the same message again there by ensuring that the product was added to the order.
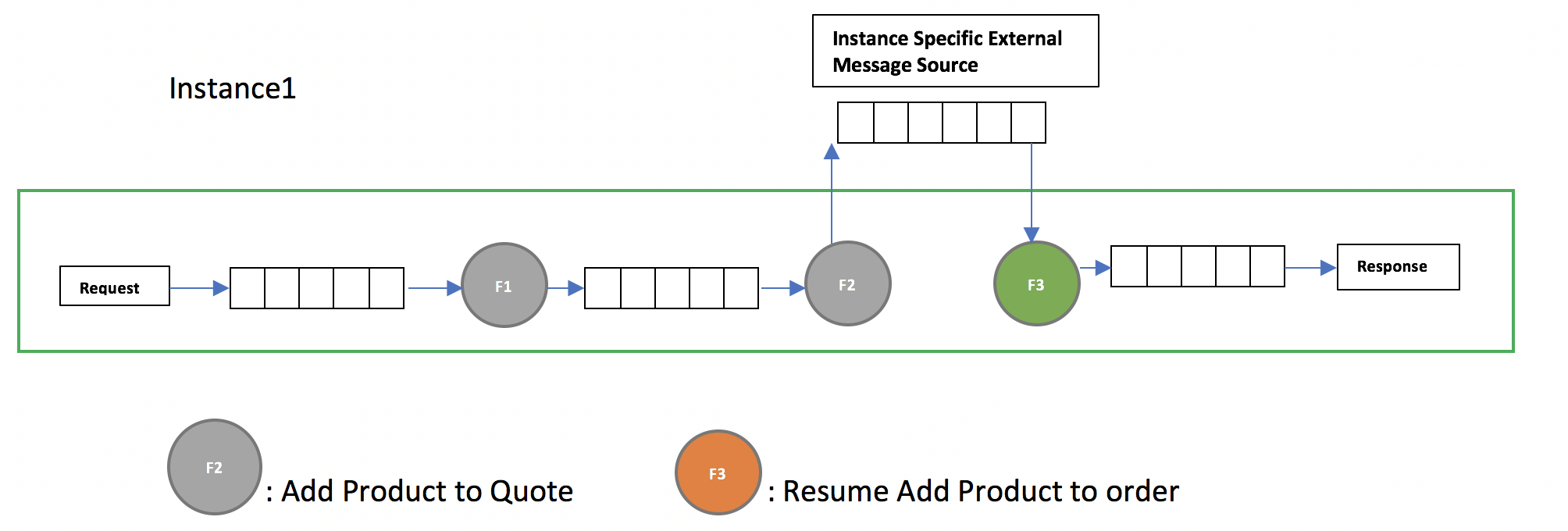
Instance specific External Message source in ECOS
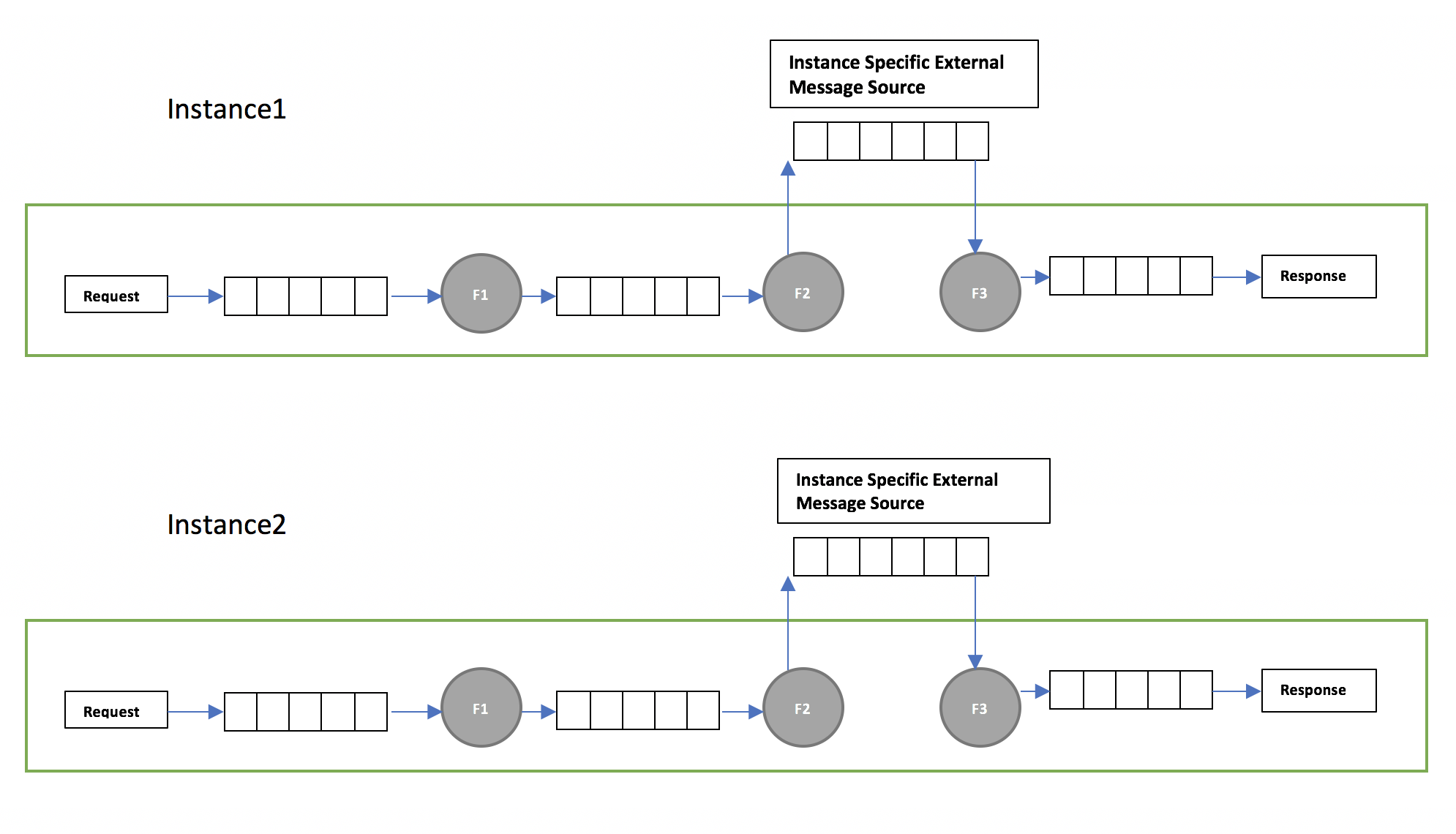
Now that we have the background on why we need external system for saving the state(persistence or a queue) to achieve durability, the subtle question to be answered is can we have a single queue? In other words Can all the instances share the common queue to save the intermediate state.
The main problem with sharing the queue across multiple instances is that on receiving the request from the client ‘C’ by an instance ‘X’, only that particular instance ‘X’ can respond back to the client ‘C’ after all the processing is done. By sharing a queue across all scaled out instances, we will loose the control of which instance picks up what. As result of that it is possible that the intermediate state event in the queue can be picked up some other instance ‘Y’ and there is no way for that instance ‘Y’ to respond back client ‘C’.
This meant that in order to respond back to the client and also ensure durability in ECOS we need instance specific queue.
Idempotency in ECOS at the Request Level
In the context of ECOS, idempotency is extremely important. For instance In addProduct If a request was processed completely in ecos, and if there is a failure either on the client side or on ECOS before sending the response back to client, the client will retry the same operation. This will result in executing the same operation multiple times which can introduce anamolies in ECOS.
The idempotency of requests can be solved by assigning the IdempotentId to the request(which can be the requestID itself) and assigning the state as started/completed/in-progress for that IdempotentId and updating the IdempotentId state in the centralised cache . Now if a request was made with the same IdempotentId again, Immediate response can be sent that the operation is already executed.
Adavantages of piping the micro-modules
- This kind of design gives you flexiblity in piping the micro modules together in a resilient manner without compromising on the scalability aspect.
- higher durability in the system. Note: Durability in terms of operations is the guarantee/commitment that this operation will be executed.
- Failure Recovery: Having Durable records ensures we can recover from abrupt failures if there are any and make sure the system is consistent
- Loose Coupling of micro modules
- Flexiblity in bringing in new changes for different projects in ECOS.
References: https://docs.microsoft.com/en-us/azure/architecture/patterns/pipes-and-filters