Consensus in Distributed systems - Part 1
Atomic distributed transaction
Transaction is a set of operations which are either executed or not executed at all. In other words the state of the system is a result of the complete
execution or no execution at all. Achieving transactional behaviour in distributed systems is not quite trivial. The problem becomes more interesting when we are dealing with asynchronous distributed systems where the assumptions about time and order of events in the system does not hold. Even in Synchronous distributed systems, where are there are strong guarantees about clock and order of events things can go wrong, if not handled properly.
The set of operations are executed across multiple hosts so that the final state of all the hosts are same as a result of execution of the transaction. This is also termed as Distributed Atomic Transactions. It is a variation of consensus problem where a set of hosts are agreeing on a value. In this case set of nodes are agreeing on whether to commit/abort a transaction.Linearisable Consistency/ Serializability
Distributed atomic transactions, state machine replication, Leader Election are all the variations of the same problem “Consensus”.
Consensus (Single vs multi value)
The problem is as simple as agreeing on a single value amongst a set of processes.I wish it was as “simple” as I have quoted. It becomes more interesting when you add a little bit of chaos where the processes can be faulty or fail while the consensus is being achieved.The processes must somehow put forth their candidate values, communicate with one another, and agree on a single consensus value.
There are many distributed systems where electing a leader is a trivial requirement. But the question is for electing a leader why would you need consensus.
The reason is to avoid multiple leaders in the system. So the consensus ensures that there is only one leader selected amongst a set of nodes. Having multiple leaders can lead to serious issues in distributed systems like split brain.
The other variation of consensus is Replicated State Machine or multi value consensus, where in a set of machines should have execute the same sequence of operations to reach the same state. Here a set of nodes agree on multiple values but the order of accepted values is important.
I would also like to quote another sibling of Consensus, “atomic_broadcast” which is the ability to deliver messages in a network reliably and in a total order to all nodes.Messages here are delivered “atomically”: every message is either delivered to all processes or to none of them and, if the message is delivered, every other message is ordered before or after this message.
Set the goals right before starting
Distributed systems are all about handling failure scenarios, guarantees and assumptions.Lets set these right before getting into water.
Safety and liveliness
All family of consensus protocol has to adhere to safety and liveliness.
The safety property ensures that only one value is chosen. The liveliness property ensures that a value is chosen eventually. But I personally like the below definition
"Safety properties say that nothing bad will ever happen".
"Liveliness properties say that something good will eventually happen".Agreement, Validity and Termination
1. Agreement is pretty straight forward where all N nodes agree on a single value.
2. Validity ensures the validity of the agreement. i.e. only the value that is proposed should be agreed.
3. Termination ensures that all nodes eventually agree.One subtle thing to note is that if all nodes always agree on a default configured value, Even though agreement property is met , Validity is not met.</i>
Fail stop and fail Recovery
Failure of nodes is inevitable in distributed systems. While the consensus is in progress the nodes might fail. If a node fails and never recovers, It is termed as fail-stop mode. Incase if the node recovers, it is called fail-recovery mode.
Assumptions
Following are the assumptions related to failures that can happen while the consensus is being achieved.
- failure of nodes
- delay in messages
- lost messages
- Value must me decided as long as the majority of nodes are available
There is a separate class of failure called “Byzantine Failure”. The assumption we have set is that none of the consensus protocols have this mode of failure. There is a nice post on why consensus cannot be achieved in a system with one faulty process in asynchronous environment. link.
Actors in Consensus
Proposer: This actor is responsible for proposing a value. He is also responsible for handling client requests.
Acceptors: This actor responds to proposers message. Its response represents votes for the consensus. Stores the chosen value. Discovers the chosen value.
A node can be a proposer, acceptor or even both.In all the below example we will assume that node is both proposer and acceptor.
Consensus protocols
1.1 Simplest Consensus protocol Single Acceptor
We can have a single acceptor decide/chose the value amongst a group of nodes. The problem with this approach is if the acceptor node dies immediately after receiving the proposed value, then we can no longer decide the value. Hence it is required for the consensus to be reached when the majority of nodes are available.
1.2 Quorum number of Acceptors
To solve the previous problem we can have multiple acceptors in the cluster and have them accept values proposed by the proposers. However the problem with this approach is it is possible that different acceptors might accept different values during multiple proposals depending upon the order in which they receive the proposals. In the example below it is possible that servers s1,s2 might accept red, while s3,s4 might accept blue and s5 might accept green. This kind of also gives an intuition and reasoning to claim that we need more than one rounds to reach proper consensus.
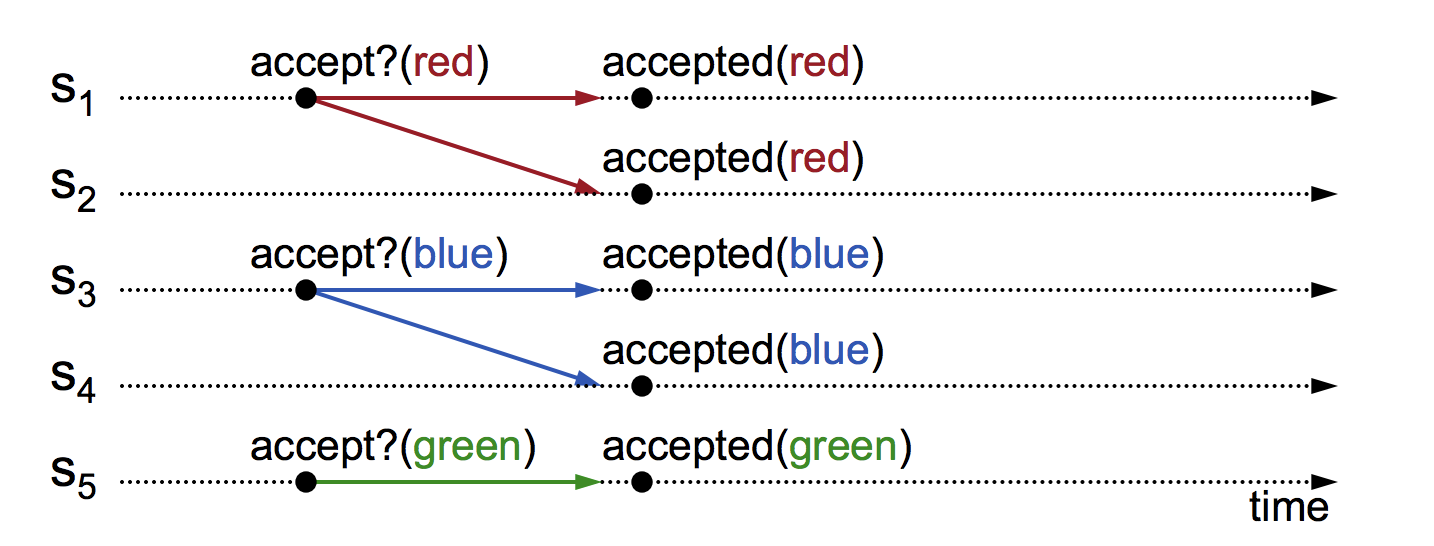
Note that just because a value is received does not mean it is chosen. A value is chosen only if a majority of Acceptors accept the same value. So after receiving a value , the acceptor might ask permission from majority of nodes whether to accept or not. IF majority is met then that value is accepted. In the below example, “red” is accepted after majority of nodes s1,s2,s3 accepted it.However, when there is another proposal for “blue”, again majority is met, resulting in accepting “blue”. This violates the safety property.
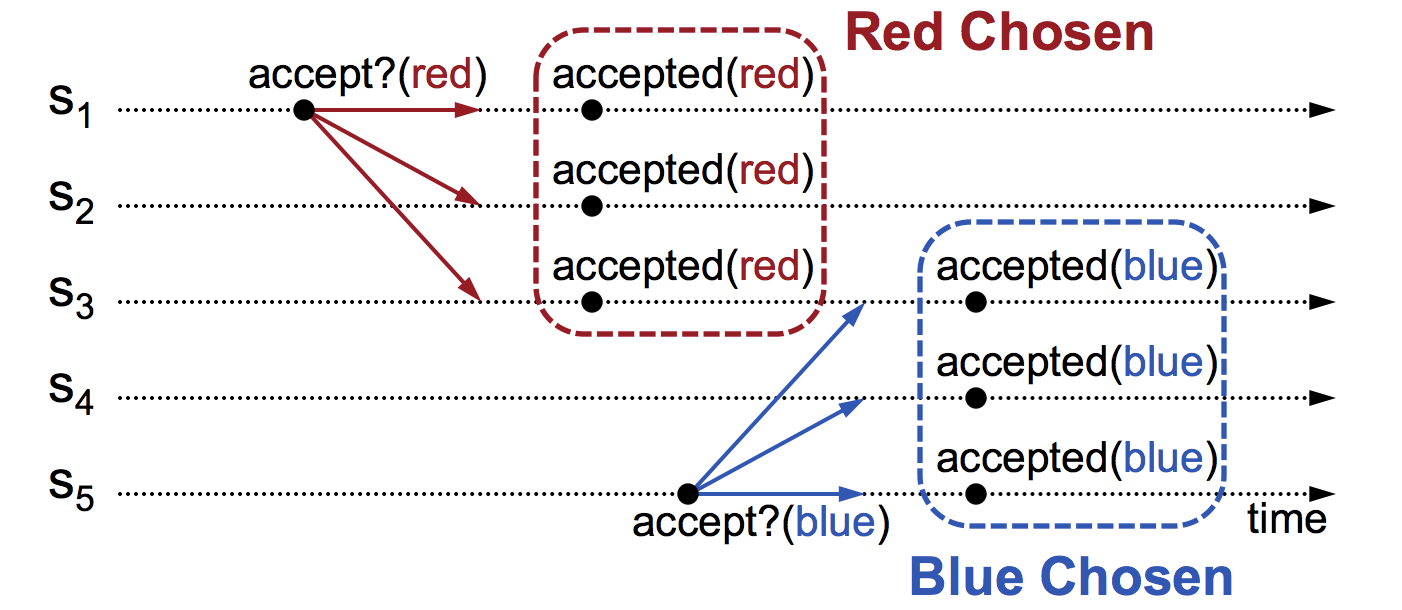
The problem with above method is that the acceptors accept every value they receive. If we can avoid this by ensuring that once the value is chosen, the chosen value is reproposed by the new proposer. In the above case , s5 must check to see if there is a value chosen already before proposing “blue” . Since “red” is already chosen, a5 must propose “red” again.This leads us to 2PC.
1.3 Two-phase protocol - 2PC
The 2PC is the simplest consensus protocol and the more obvious sounding algorithm. There are many variations and optimisations that are done on 2PC, I will be refering to the generic 2PC consensus protocol.
In 2 phase protocol there are 2 phases.
- propose phase : The coordinator proposes a value to majority of nodes and gathers response.
- commit/abort phase : Based on the response, the coordinator either sends commit/abort to majority of nodes.
In 2PC the coordinator orchestrates the whole flow. Once the co-ordinator gets the response from majority of nodes it either commits/aborts. 2PC adheres to validity property since the co-ordinators’ proposed value is accepted not the default value. Termination is ensured by co-ordinator by commiting/aborting the proposal. Safety is ensured since only single value is accepted by nodes. All these properties hold good under happy scenario where there are no failure of nodes.
Failure cases in 2PC
Things start to break with 2PC when there are failures in the system.
- In Phase 1 if the co-ordinator fails before proposing, there is no impact on the consensus, since the co-ordinator did not propose any value.
- In phase 1 if the coordinator fails after proposing the value to few nodes(not to all nodes/majority of nodes), This might cause the consensus to halt since the “Received nodes” would have sent their votes to coordinator and are waiting to get the commit/abort from coordinator.The protocol is therefore blocked on the coordinator, and can’t make any progress. We can add some mechanisms to deal with this - but this problem of being stuck waiting for some participant to complete their part of the protocol is something that 2PC will never quite shrug off.
- In Phase2 if the co-ordinator sends commit/abort message to few nodes and fails before sending to all nodes, then there is no way to know if all replicas got commit/abort message.
Another subtle issue to notice with 2PC is the timing of multiple proposals can cause the system to agree on more than one value. Lets take the below example. Here s1 before initiating the 2PC checks to see if there are any proposals in progress, since there are none it initiates the consensus. similarly s5 checks to see if there are any proposals in progress, so s5 also initiates the consensus. As a result of this the order in which the proposals reach the nodes results in having more than one value being accepted. s3,s4,s5 accepts “blue” during the initial consensus. Later s1,s2,s3 end up accepting “red”.
Hence there is a need for ordering the proposals and also rejecting old proposals.
1.4 Three-phase protocol - 3PC
The problem of 2PC was that the failure of nodes/coordinator caused the system to fail on reaching consensus.This can be solved by breaking the 2nd phase of 2PC into 2-sub phases, “prepare to commit” and “commit/abort”.
1 The first step is similar to 2PC.
2.1 The prepare to commit phase allows the co-ordinator to propagate the votes it received in phase1 to all the nodes. The nodes now prepare to commit by acquiring resources and locks but not do anything that cannot be reverted.
2.2 Later the last phase is similar to the 2PC where the co-ordinator issues the commit/abort.
Failure scenarios in 3PC
The addition of “prepare to commit” step allows the 3PC to recover from the failures of co-ordinator or the replicas.
- If the co-ordinator fails before/after the “prepare to commit” step or after it has sent commit message to few nodes, the recovery node can continue by querying the state from other nodes.
Case1: If the co-ordinator dies after sending “prepare to commit” to few nodes, the recovery node realises that there are replicas who have not received the “prepare to commit” message, it can be certain that the co-ordinator would have not moved to the “commit phase”. And hence it can either abort the transaction or restart the protocol again.
Case2: If the co-ordinator fails after sending commit message to few nodes, now when the recovery node takes over it can query the state of the protocol from he replicas, it realises that few nodes have received the commit message , now it is safe to commit the transaction since it can be sure that the co-ordinator has moved to the commit phase only after all the nodes have received the “prepare to commit” message.
-
If the co-ordinator dies after sending commit message to few nodes and the replicas which received the commit message also died. Now the recovery node queries the state of the protocol from the available replicas , all of the available replicas would return “prepare to commit” state. In this case , the recovery node can either wait for the crashed node to recover in order to query its state. This is important because the recovery node does not yet know if the failed replica really received the “prepare to commit” message. This wait can be indefinite which can cause the protocol to fail the liveliness property. or if the recovery can tolerate ‘f’ failures it can continue to commit phase after receiving f+1 messages from the available replicas. There by ensuring the liveliness property.
-
Network Partition: In case of network partition, it is quite possible that both partitions recovered an outstanding instance of the protocol to different conclusions, leading to an inconsistency when the network remerges. For instance, if we are so unlucky that all the nodes that received “prepare to commit” are on one side of the partition, and all the nodes which dint receive are on the other side, we will end up commiting in one partition and aborting in the other.
Having said that, Is Network partition really a trivial problem? or Can we live with it? It depends on how precisely concerned we are with the system in place. If we are complacent about the details, 3pc can still be used. Unlike 2PC, 3PC will always make progress. It is still a fairly good choice given the fact that it does not block on node failures.
3PC algorithm assumes a fail-stop model, where processes fail by crashing and crashes can be accurately detected, and does not work with network partitions or asynchronous communication.