Why?
Most enterprise platforms are event driven. Event driven services are at the core of the design that drives the business. Having fault tolerance and auto recovery mechanism is a must specially when u are dealing with business and operations critical functionality. The reason why it is important to design auto self healing services is the fact that manual recovery is extremely tedious and time intensive which can have a significant business impact.
My experience working with Event driven Business critical services
Designing a retail platform for handling the orders right from creation till Fulfilment involves a lot of services and eventing becomes the core of the platform. In simple words, a typical event consumer service gets an event, runs some business logic, updates its resources state, and notify about its state change. Doing this idempotently and resiliently determines the whole success of the business in handling customer impact. Over a period of years I have used multiple approaches ecah having its own flavour. My other postDistributed Transaction management in Cloud Native Architectures highlights the challenges and approaches specific to distributed transaction management in Microservices Architectures.
Sample Usecase
I have experience designing the architecture for customer order and fulfilment platform in Tesco right from order placement till its fulfilment and payment. I would want to discuss one aspect of the post checkout journey, where the design is completely event driven. Lets take a use case so that it is easier to empathise the problem. Different services including customer order service, fulfilment service , picking service and transport service all emit and react to different domain events and take some actions. I would want to focus on one such journey where the business impact is very massive. Once the picking happens, the customer order service is responsible for repricing the order due to substitutions/unavailability of products, take the payment, generate the invoice and and later let the fulfilment services continue to delivery of the order.
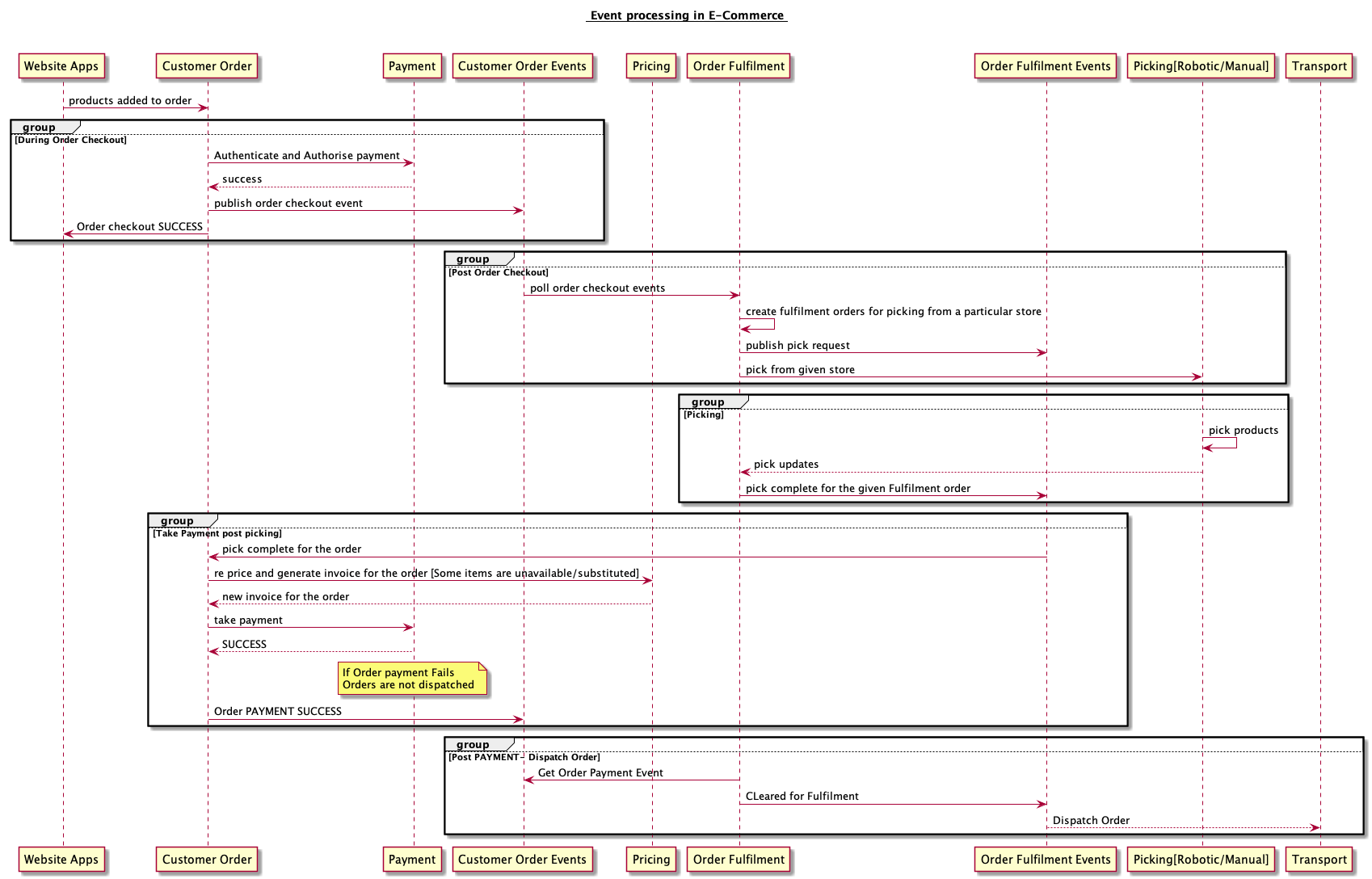
Key thing to note is the business impact.
- IF the picking event is not processed successfully, all the transport delivery vehicles will be held waiting for clearance for fulfilment.
- IF the payment fails for the picked order due to payment service being down or the payment details are no longer valid resulting in payment failures.
- IF the picked product data in the picked event is invalid like picking something that does not exist in the system. [Oh yes it does happen]
Note: I have taken the invalid payment error specifically to highlight the importance of thinking through the domain errors and work with the business folks to get inputs on recovery mechanisms.
Tesco has a unique case where the payment for an order is not taken immediately when the order gets checked out. Instead the payment is just authenticated and authorised by the customer during checkout. The actual payment transaction happens only post the picking to account for the price on the day of picking and substitutions. Now the payment details that were entered during the checkout could no longer be valid when the actual payment transaction is tried on the day of picking.
Error categories
We can broadly categorise these errors into
- Transient errors : Errors that can be recovered after some time . [Some agreed time Window]
- Non transient errors : Errors that cannot be recovered with in the given time window.
- Retriable errors: Errors that can be retried later. Most transient errors fall into this category.
- Non Retriable errors : Errors that cannot be retried ever. Most non transient errors fall into this category.
In General , we are looking at below cases.
- Recovering from dependency service failures [ Transient error ]
- Recovering from faulty state [ payment failures due to invalid payment details on the day of picking] [ Transient / Non Transient errors ]
- Recovering from the invalid data in the event. [ Non transient errors ]
Setting up the stage
Before we get into the details of the solution, lets get our nomenclature right.
- Main Queue is the main source of domain events
- Retry Queue is something that we refer to as queue with events that can be retried.
- DLQ is basically the dead letter queue for auditing and manual recovery.
- DLS is Dead letter store is basically a data store (key/value, sql, nosql) which is used to store the events. This allows for beter query and auditing compared to DLQ due to the limitations of adhoc querying the queued events.
- Dependent services could be domain API services/ Data stores / Event stores
Key Challenges
- Event Ordering
- Batch processing
- Concurrent processing of events across multiple queues
- Recovering from Partial failures idempotently
Importance of Ordering of events
Some applications demand strict ordering of the event processing. The ground rule is that for a given event consumer all events related to a resource, needs to be processed in the same order.
Eg: Lets say if the resource is the order o1 , all events related to the order [released for picking(e1) , picked(e2) , out for delivery(e3) , delivered(e4) and so on] . This is important because u do not want to process the events e1,e2,e3,e4 out of order. This is a clear domain requirement and crucial for resource data integrity.
The solution needs to take care of ordering of events related to the same resource even when processing across different queues including Main/Retry Queue.
single vs batch processing of events
Whether the event consumer is processing one event at a time or processing multiple events at a time in batch also affects your recovery mechanisms.The solution needs to handle both cases.
Note: Before we get into the recovery mechanisms the key thing to note that there is no one size fits all solution. Meaning we need to be pragmatic about the domain and the workflow and decide what fits the best.
Concurrent processing of events across Retry/Main Queue
The solution needs to take into account the possibility of concurrently processing the events related to the same resource.
Recovering from Partial failures while processing the event in an idempotent manner
Successfully consuming an event may include interacting with multiple other dependent services, updating the change in state of its resources in data store and probably publishing an event to indicate the change in state. If there are failures during any of the step, recovering from that partial failures is also critical for the solution.
Self Healing and Recovery mechanisms
Case1 : Recovering from dependent service failures
Please note that the dependent service can be a data store/ API service / event store.
- Retry Queue with exponential backoff
The idea is to publish the failed events from the main queue to the retry queue which can be later processed. The retry queue implementaion is a generic approach. The devils lie in the details of the design and usecase. Lets try to dig a bit deeper.
The key challenge with this approach is to handle concurrent processing and out of order processing of events of the same resource (order) both from Main and retry queue. Depending upon the design choices, there are multiple options.
-
Solution 1: Prevent consumption from main queue until all events in retry queue are processed for that resource(order).This works and is simple but the downside is throughput and starvation.
-
Solution 2: If there is an event of a given resource in retry queue, all subsequent events of that particular resource are pushed to retry queue. This will prevent concurrent processing from main/retry queue, starvation in main queue for other events and most importantly ordering. This requires additional metadata being maintained to know that there are some events pending events in retry queue. Once all the retry pending events are processed, we can continue to process other events from the main queue as before.
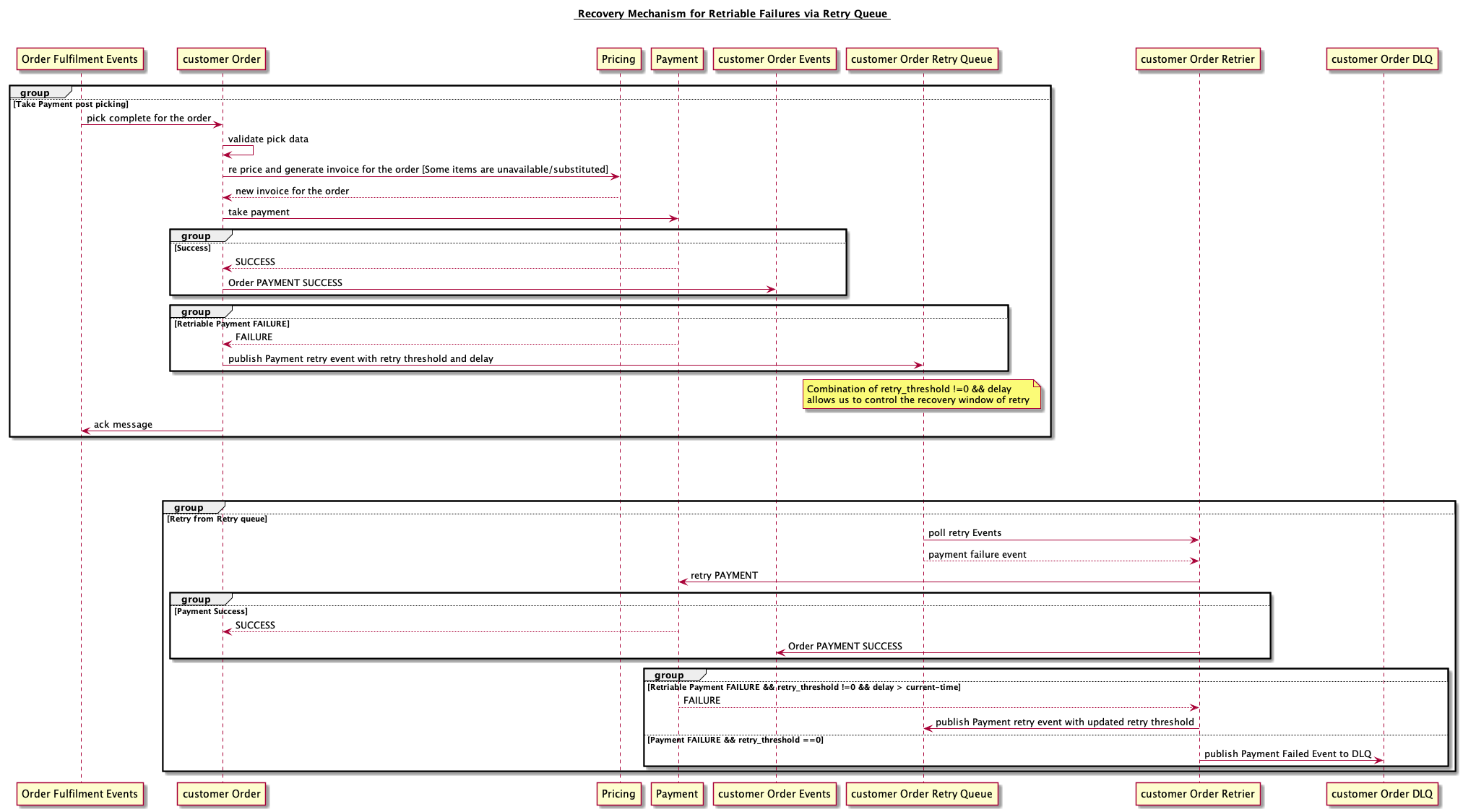
- Solution 3: Have multiple levels of Retry Queue with different retry threshold and frequency. Later followed by a DLQ after all retries are exhausted.
Side Note: Importance of being idempotent in event processing due to partial failures
The definition of idempotent in this case has a different flavour. An event[e1] consumption would result in a state transition of a domain resource [r1] from state1 [s1 —> s2]. The challenge is to ensure that the target state of the resource [r1] is s2 no matter what failures we encounter or no matter how many times we consume event e1. There should not be a case where the resource r1 gets into incorrect state other than s2.
Achieving Idempotency is no easy task. There is no one approach that fits all use cases and scenarios. My other postIdempotency in Cloud Native Architectures highlights the challenges and approaches in detail.
Case2 : Recovering from Non Retriable but transient errors:
The second case is interesting, it can be treated as a transient error and non transient error. It is transient when the invalid data can be corrected allowing the systems to recover by retrying later. Deciding whether some error case is transient or non transient is crucial and working closely with the product/business will help u in deciding it. Recovery can be manual [involve support teams], semi automated/ fully automated. It depends on case by case.
Solution 1: Data / Error / Control Channels Have the error flows worked out end to end across multiple business domain to have recovery mechanisms in place.
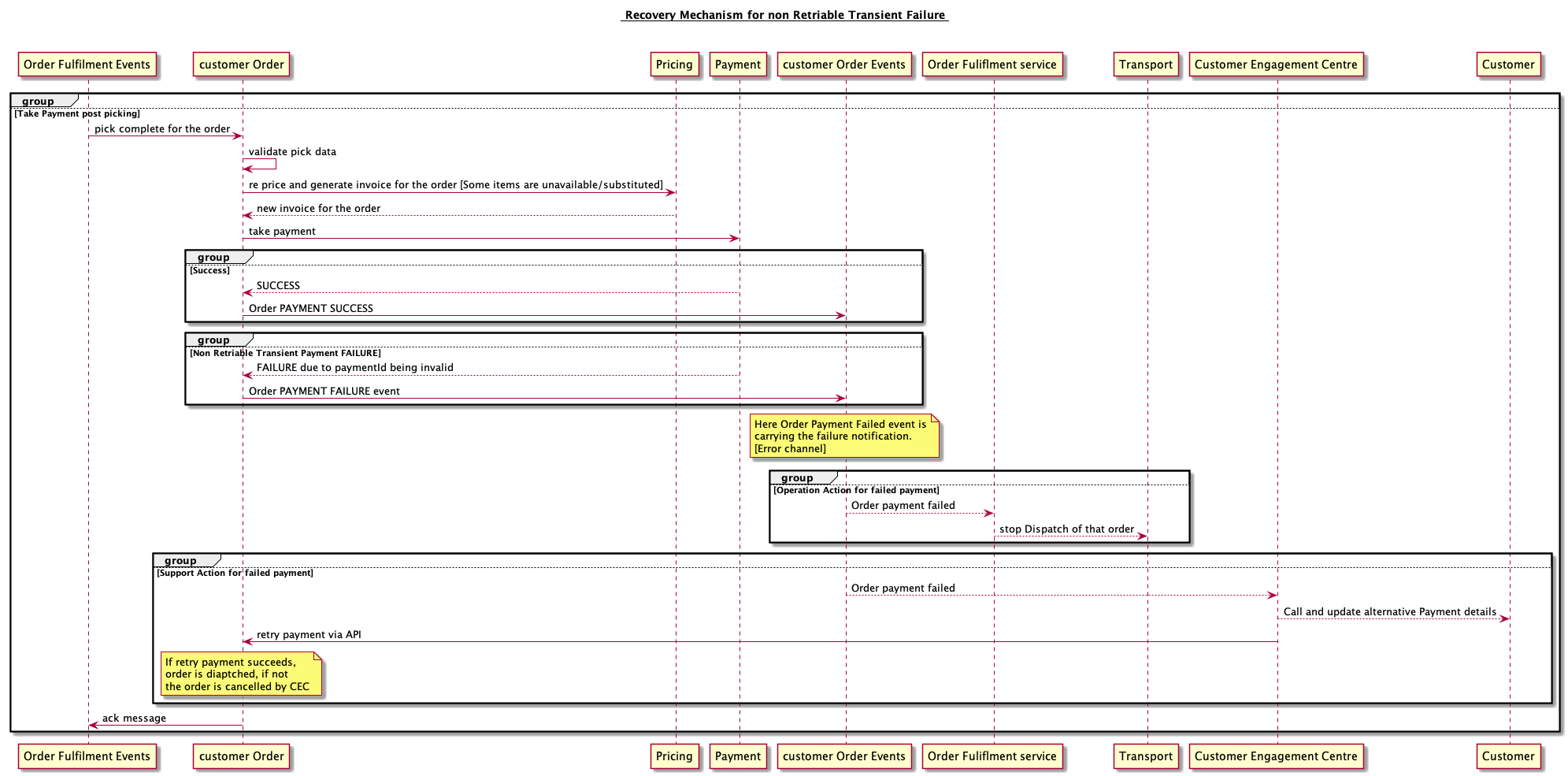
The idea is similar to reactive programming, where we have data, error and control channels. The data channels carry your domain events, error channels carry your faulty states, errors, and control channels carry the control events like circuit broken events/event processing stats/event to let producer slow down. This is an interesting design where we are trying to build an efficient and cloud native event processing design.
The choice whether to use the same topic/queue to propogate data/error/control events is upto the designer.
Example for stale data: For instance, when the customer checked out, the payment details were valid. But after picking which can happen sometime in future, the same payment detail can be invalid. In this case we can actually reach out to the customer and ask the customer for alternative payment details and retry the payment before delivering the order. However if we presume that the payment details are invalid we could just cancel the order stating invalid payment details resulting in business loss. Involving business folks to get their input on customer experience is very crucial. Tesco being extremely obsessed with customer experience, they would go to an extent where they will deliver the order and later take payment from the customer. Given the occurance of this very low, we have a payment retry mechanism, where support team actually reaches out to customer and ask the customer for new payment details and retry the payment before delivering the order.
Case3 : Recovering from Non Retriable Non transient errors:
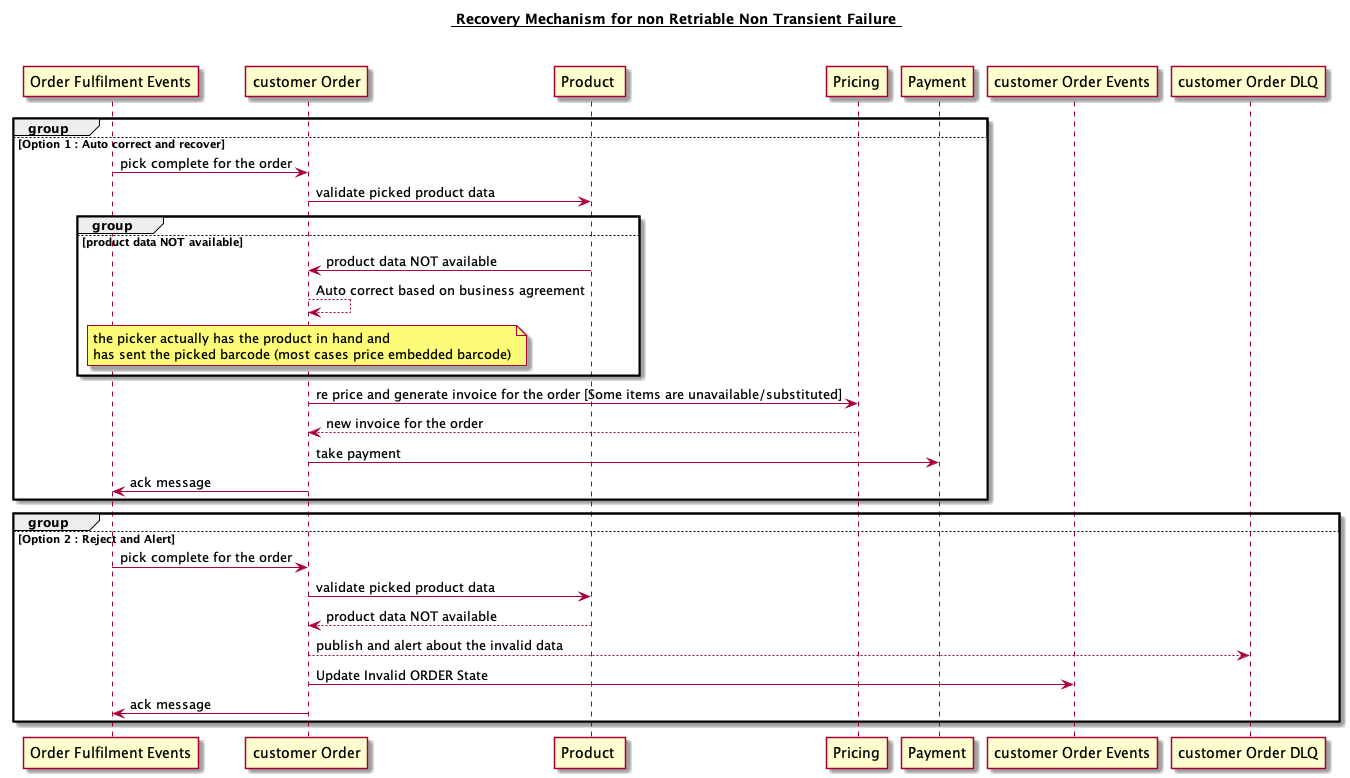
The cause for Non Transient errors could be incorrect data in the event or incorrect operation by the dependent services. The reasons could be faulty production deployment of our own service or the event source or due to an operational inconsistency. Recovering from these errors is equally crucial to ensure other events in the queue are not starving.
Solution 1: Auto correction mechanisms There are some cases where the invalid data in the event could be due to incorrect service or operational inconsistencies. Example: If a picker picks a product as a substitute, but the same product is not available in the Product service. The key thing to note is, the picker actually has the product in hand and has sent the picked barcode (most cases price embedded barcode). In such cases, instead of erroring out due to incorrect data in services, work with the business folks to understand the recovery mechanisms and build automated recovery process.
- A simple recovery mechanism could be, mark the price for that product as markedprice if available or give it for free. instead of blocking the whole order. Alert the relevant service to correct the data inconsistencies.
Solution 2: Use a separate DLQ/DLS to investigate and query these invalid events Once the errors are identified, we can publish those incorrect events to DLQ/DLS for further investigation and alerting. The same DLQ/DLS can also help in replaying the events after correcting the data.
Summary
Recovering from Retriable failures : Retry Queue with exponential backoff Recovering from Non Retriable but transient errors: Data / Error / Control channels Recovering from Non Retriable and Non transient errors: Auto correction mechanisms and alerting
Few Tips before we close off:
Tip 1: Having a circuit breaker in place while consuming events from the main/retry/DLQ will prevent too many events ending up in retry/dlq and not to forget the load on the dependent system.
Tip 2: Having support APIs can be very beneficial in production. For instance having an API to directly post an event to retry the whole event consumption can help u recover from faulty states and resolve issues.
Tip 3: Involve business to get answers from business perspective and analyse the impact and have workflows to recover from exception scenarios.
Tip 4: There is no one approach that fits all use cases and scenarios. Use a combination of the above try to come up with your own approach and most importantly solve the problem in hand and never try to fit the approach into the problem.