Resiliency Matrix for Cloud Native applications
Why?
Facilitate asking the right questions w.r.t the new feature and analyse the customer impact and make better decisions upfront.
Rather than reacting to incidents in production, build a resilient product by making informed decisions to handle most possible scenarios.
Capture the approach and customer impact in a single place for better assessment of the feature DOD.
Assist in validating all resiliency related workflows upfront during
* Refinement
* Discuss the expectations around failures across different services
* Discuss the fallback options
* Discuss the customer impact and resolutuion
* Development
* Ensure all discussed failures are handled in code
* Ensure suitable design is in place for all possible resiliency scenarios listed
* Review
* Ensure required error handling and resiliency is taken care of while reviewing
How?
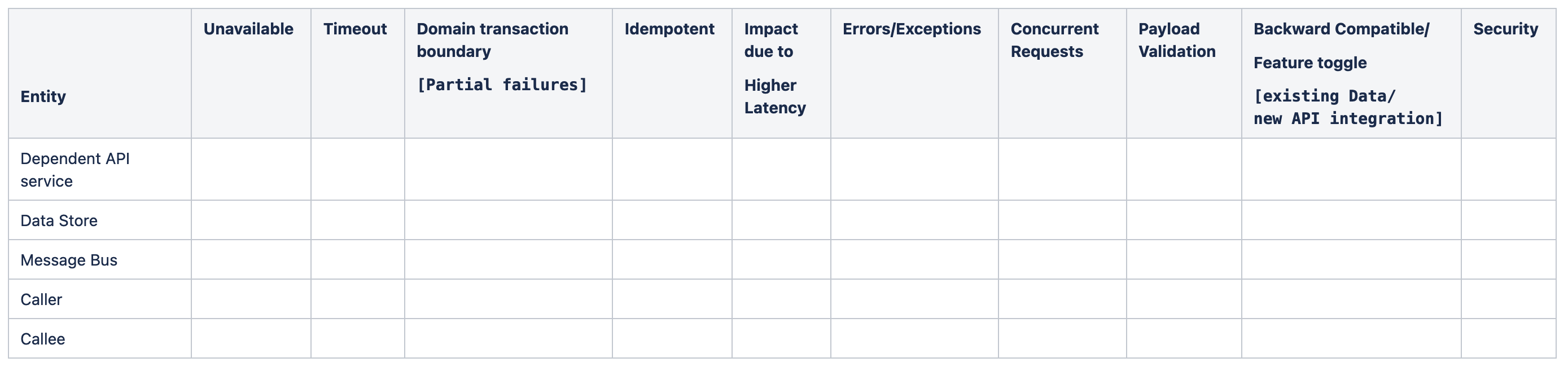
Usage Guideline:
* Discuss the resiliency aspects related to the feature upfront during refinement.
* Try to analyze the impact with different entities as given below and fill in relevant information
* Asking the right questions with different entities and different kind of impact.
Example: the way to use the below table is:
* If the Dependent service API becomes unavailable, what should be done
* If the Data store call is throwing timeout, what should be done
* Is the Data store operation idempotent
* Are the Data store errors or exceptions retriable?
* What if the API caller becomes unavailable/times out after calling the API, what is the customer impact
Example: ADDFG call
Here is a sample Resiliency Matrix that captures the different events w.r.t interactions with transport API for reservation
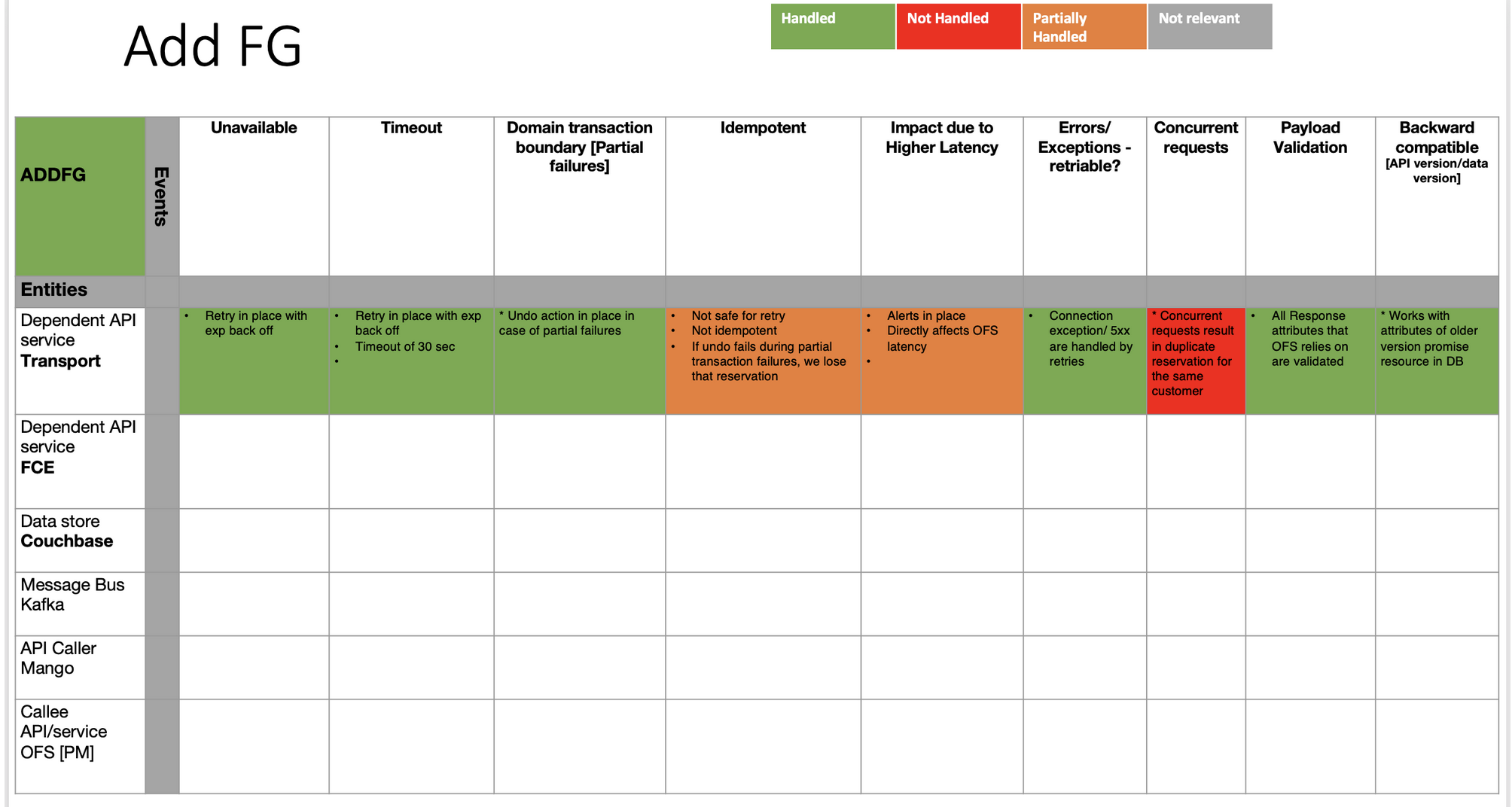
Key terms:
Domain transaction boundary:
This can include multiple business steps as below. The transactionality tries to achieve either all the operations or none.
- updating a dependent API service
- updating data store
- Publishing messages
- Acknowledging the brokers in case of event consumers
Idempotent: This is to ensure no matter how many times some API/event is repeated the end behaviour/state has to be same from the domain consistency perspective.
Handle Concurrent updates on the same resource: This is to ensure the race condition does not corrupt or put the resource in an incorrect or inconsistent state.
Entities:
- Dependent API service
- Dependent Infra
- Data store [Couchbase,cassandra,MySql]
- Event Bus [Kafka,RabbitMQ,ActiveMQ]
- Cache [Redis,Ehcache]
- Caller of the API [Mango/ECOS/FPS]
- Callee [OFS service/API]
Events:
Unavailable:
What is the impact on the caller? Is my service availability impacted? What if I (API service/consumer) go down/become unavailable in between before responding? Do we fail or continue is dependent service/infra is unavailable? Is it part of the critical path? If it is part of the critical path and it is a point of no return, how do we recover later? Alerts for the same
Timeout:
How do we handle timeouts? Is retry safer? What is the ideal timeout? What is the impact on our service with very high timeouts? Alerts for the same
Domain transaction boundary:
Is it part of the transaction boundary? Is it a step with point of no return i.e. We have to ensure all subsequent operations are completed eventually? How do you recover from partial failures? Is eventual consistency in transaction boundary acceptable? Alerts for the same
Higher Latency:
is higher latency acceptable? What is the acceptable max latency? Is Circuit breaking necessary to give a breather to recover dependent service/infra? Is there a fallback during higher latencies? Alerts for the same
Idempotency
API/Event consumer How long are we supporting Idempotency for a request? Can I retry the API request after one month? Will it still be idempotent? Idempotency on failed requests in Api services? Do we rely on the state of the resource or unique requestIds for idempotency? Example: canceling an already cancelling FO, processing duplicate events
Errors/Exceptions - retriable?
Is it a retriable error? Is it safe to retry? Does it have side effects due to retry? What idempotent key to use for retry? Alerts for the same How do we recover from non-retriable errors specially within transaction boundary? Suitable logs for post recovery Suitable design in place for recovering later
Concurrent Requests:
Can our API be called concurrently for the same resource? Can the dependent service API be called concurrently for the same resource? Similarly for data store/kafka? How do we handle concurrent requests? Like add/remove product concurrently for the same order
Payload Validation
Payload could be from dependent api service or data store(backward compatibility) or event store. Can invalid/incorrect data in the response payload break the current functionality? How do we validate all relevant attributes in the payload and trigger error flow gracefully?
Backward Compatibility:
Is the new API integration backward compatible to our service existing data? Is the new API backward compatible? Is the new feature backward compatible to existing data in other services/API?
Security:
Validate Authentication,Authorisation,confidentiality and Denial of service usecase What is the security mechanism in place for the entity interaction? for example: is redis cache call encrypted? What is the security in place for stored data? Are relevant security threats managed from end- end perspective? Script injection checks? Payload validation for possbile security attacks? Validate different levels/layers of security Validate the authorisation mechanisms in place