Multi Region/Multi cluster Cache replication
Why replicate across multiple regions/clusters?
The hidden requirement in this design is that the data needed to serve a request is readily available anywhere for different use cases. The cache hit rate can influence the impact on the SLAs of the services. Also the load on data stores and query layers can have a huge impact depending on the availability and the consistency of data in the cache.
My experience working with Multi Region/Multi cluster Cache replication
Designing Transactional high performance business critical APIs for a retail platform requires using caching solutions in some form. My experience working with tesco in building the order service platform to handle ~40k tps was challenging and rewarding. I would like to share my experience specific to the Challenges with caching. Unlike other blogs I would like to keep this more compact.
Key challenges while designing
-
Consistency of Data in Cache Maintaining global consistency of cache data is hard. it doesn’t come for free. Enabling that would require us to deal with global locking(to prevent multiple writers from updating the same key), quorum reads and writes, transactional updates, partial-commit rollbacks, or other complications of distributed consistency.
- Read/Write operations on both clusters : Can the same key be updated by multiple writers in multiple regions
- Kind of data. Size of key/value
- Homogeneous or heterogeneous clusters
- Discovering all remote clusters
- Number of Clusters [Local/Remote]
- Cold Booting the new cluster on demand with data
- Different kind of replication operation. Replication does not mean mirroring the data operations, it could mean different operation for different kinds of local cluster update. For instance an update in local cluster could require us to invalidate the same key in all remote cluster instead of replicating the new update
- Latency and throughput : What is the acceptable latency/throughput.
- Network Bandwidth bottleneck : how do u distribute the network bandwidth work load for serving requests/replication
- Hardware choice [VM type/RAM requirement / SSD based on NVMe/SATA]
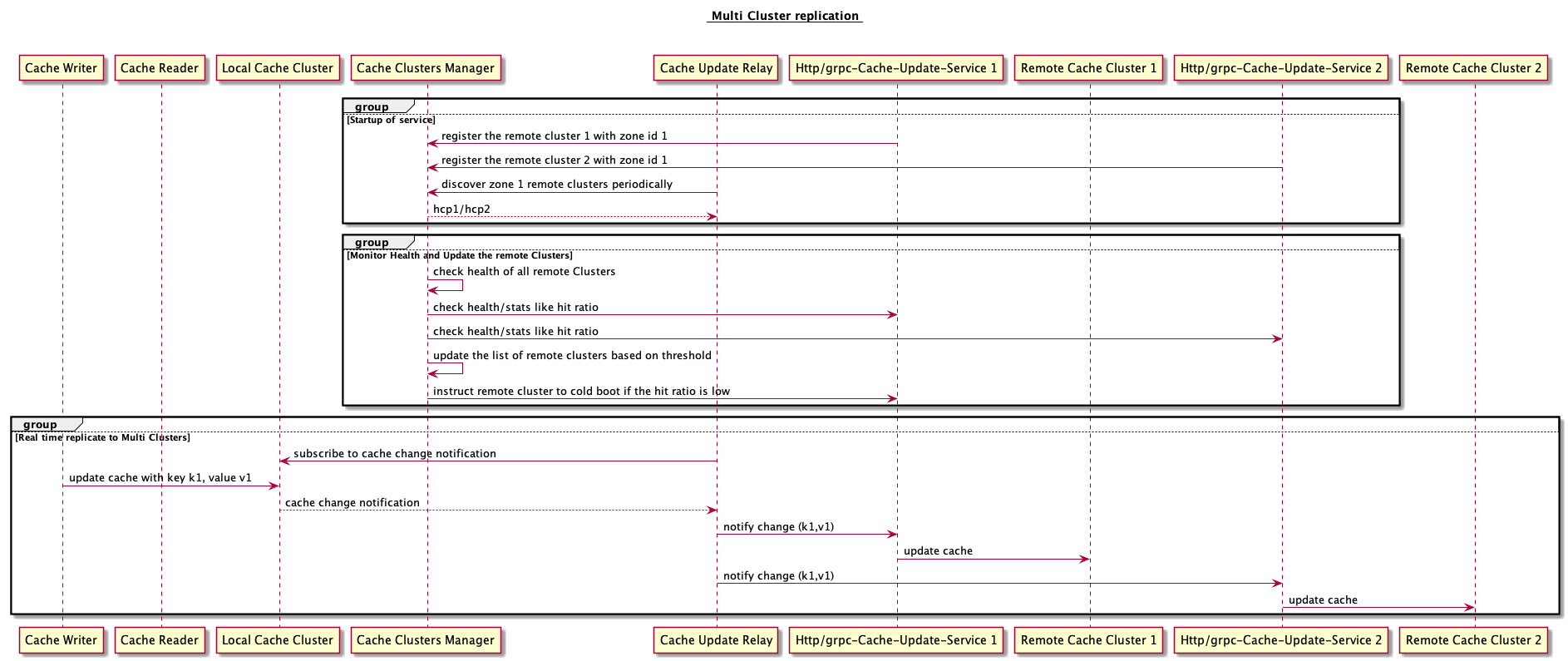
- Discovering, Monitoring and healing Multiple Remote region Clusters
Discovering and Monitoring Multiple Remote region Clusters
Imagine there are 100s of cache clusters, discovering and updating all clusters is a challenge in itself. It is a challenge to discover and monitor all the clusters across the regions and check if the hit ratio is upto the mark.
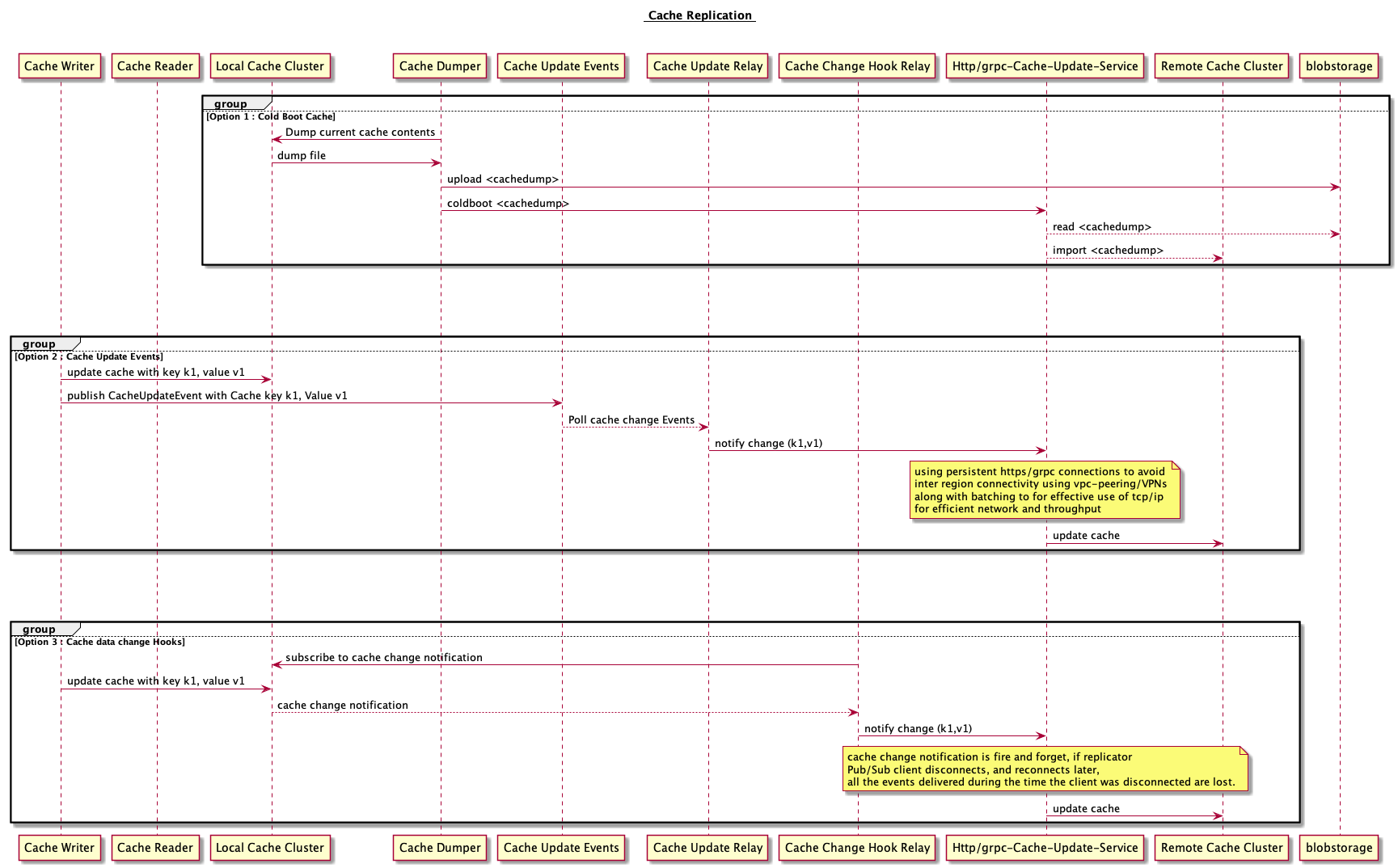
Overview of the services mentioned above.
-
Cache Dumper: This service takes the dump of the cache cluster. [sidecar/separate service to take the dump of whole cluster]
-
Cache Replicator: This service is responsible for replicating the cache data based on Cache Update Events
-
Cache Update Relay : This service subscribes on to cache data update hooks and replicates the same in remote cluster
-
Cache Cluster Manager : This service manages all the clusters. Checks the health and monitors. Enables the discoverability of the clusters for cache relays.
-
Http/grpc Cache Update service : This service exposes http/grpc endpoints for updating the cache.
-
Blob storage : This is to store the cache dump so that it can be accessed for cold booting new clusters.
Please note that I would not be able to list all the possible options and designs addressing the above challenges. This is to give you a glance of the items we need to keep in mind while designing multi cluster cache replication strategies. Below are few approaches that we had followed to address multi cluster cache set up across regions.
Cold boot or Bootstrapping the new cluster
- Export the cache dump and import in the other cluster.
- A batch uploader that reads the data from the cache in batches and updates the remote cluster. The dump and import is easier to implement when there are only 2 clusters. It becomes more challenging when there are n cache clusters. Determining where to take the dump from and instructing which importer to import the cache dump is a challenge in itself.
Dynamic cache replication Design choices
- Writer writes to all clusters
- Writer writes to local cluster and notifies about the change. Cache Replicators subscribe to these notifications and replicate the new change across multiple clusters.
- Cache data change Hooks : Cache Replicators subscribe to REDIS cache keyspace notifications and replicate the new change across multiple clusters. Redis Pub/Sub is fire and forget that is, if your Pub/Sub client disconnects, and reconnects later, all the events delivered during the time the client was disconnected are lost.
Improve Efficiency of all the choices
- Persistent https connections to reduce the chattiness
- Batched writes to improve the efficiency of data writes on the tcp connections
- Local cluster region HTTPs cache writers to prevent complex vpc peering/tunnels
The above designs are just touching the problem space, the more criterias we consider the more challenging the design becomes.