Distributed Domain Transactions in API services and Event consumers
Domain Transaction Management across multiple dependent services
Objective is to ensure that the final domain state has to be consistent as if
- either all the operations are performed
- or none of the operations are performed.
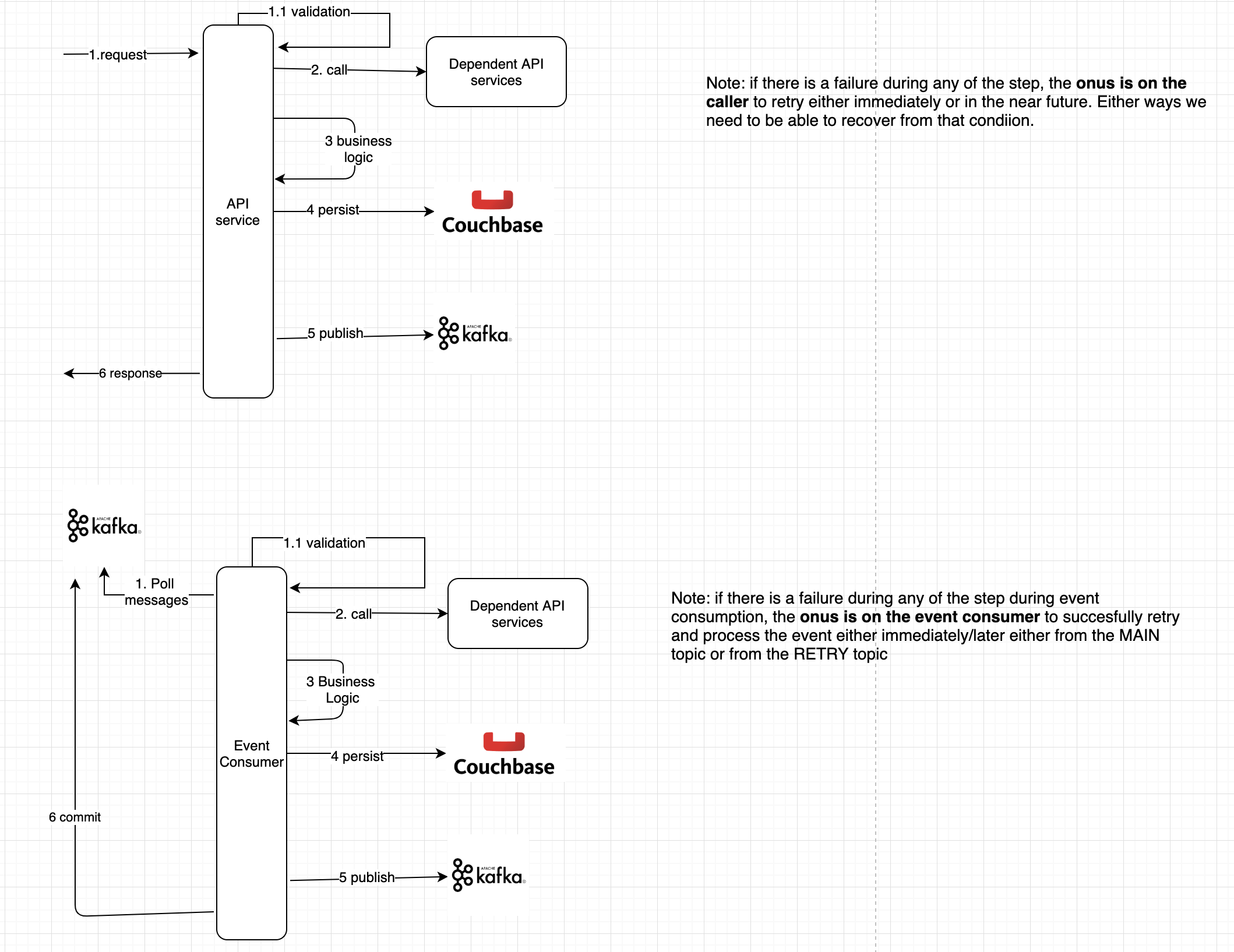
Note failures can occur during any point in the transaction boundary. Below picture depicts the transactional boundary w.r.t to an API and event Consumer. The nature of the problem is the same.
- There are a bunch of API calls followed by
- Data store update of its own resource
- Emit the event corresponding to the state change
Both event consumers and API have different flavours of the same problem. With event consumers , the retry is managed by itself, while the API recovery requires retry from the caller.
Design Options:
We need to tackle the DTM in 2 parts. One specifically to address the transactionality for dependent API services Another for data store state change and notification via eventing.
Transaction Management can be split into 2 parts:
- Ensuring Transactionality with dependent API services
- Ensuring Transactionality with data store and event store
Setting the ground rules for the dependent API services
Nature of the dependent service : State Change?
Dependent http API calls to services can result in
- State changes to resource in dependent services
- No changes in resource state/attributes
Dependent services API Maturity level?
Dependent services API maturity level
- Supports idempotency for API invocation
- Does not support idempotency for API invocation but supports reading the current state of the resource of dependent service
- Does not support idempotency and aslo does not support reading the current state of the dependent service as well
Dependent services Availability/resiliency level
All services can fail including
- API service
- dependenet service
- couchbase
- kafka The failure probability can be different. One might be more available/resilient than other.
Error Categories when interacting with dependent services:
Transient errors
- Timeouts [read/write/connection]
- service unavailable 5xx
Non transient errors: [ cannot be recovered ]
- Bad/incorrect request/data resulting in bad request [due to new releases/ data errors]
- bad/incorrect data resulting in serialization/deserialization errros [due to lack of backward compatibility in release versions]
Handling Distributed Transaction with multiple API services.
Ensuring Transactionality with dependent API services in case of failures:
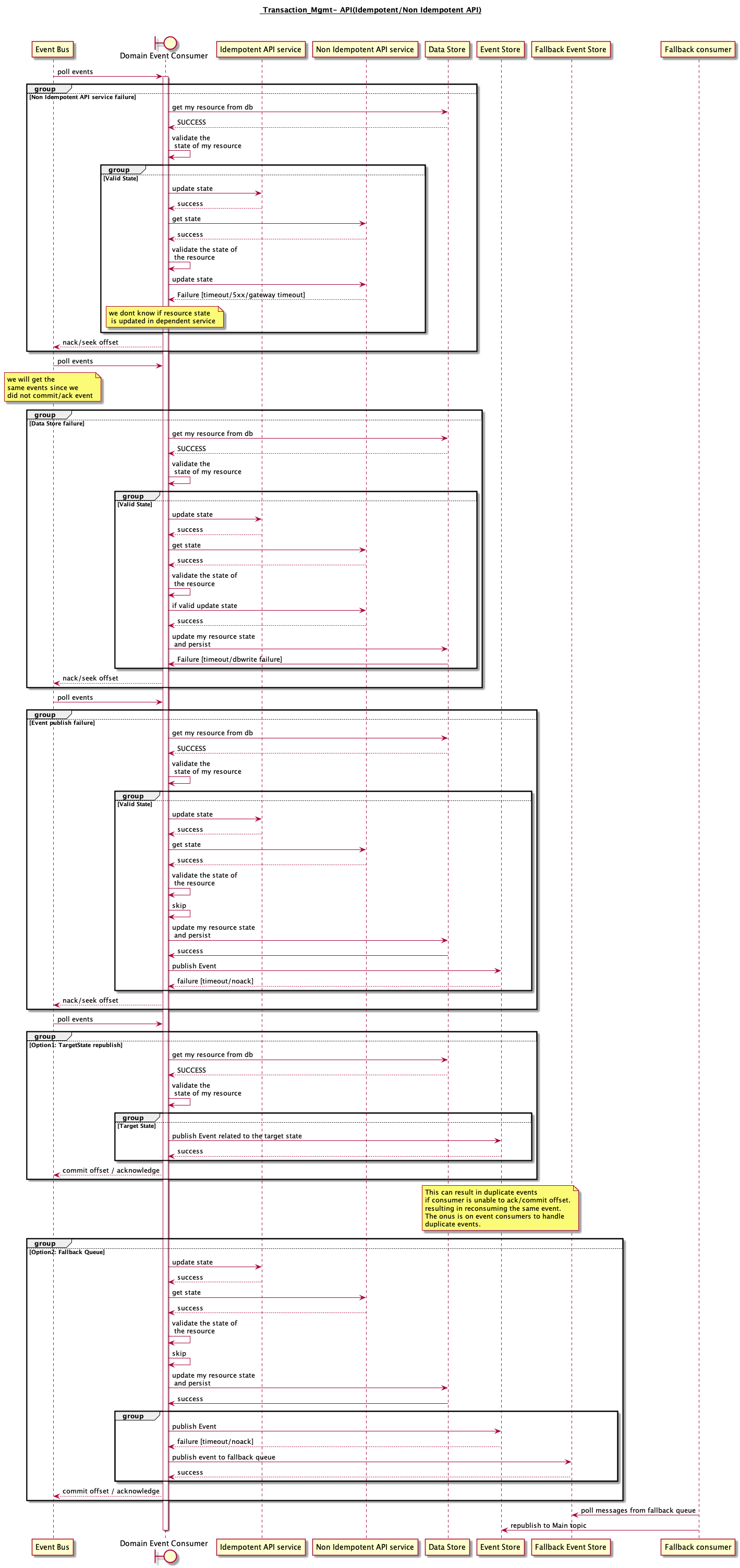
1 Idempotent API service: RETRY
- Given the idempotent nature of the resource, it is safe to retry these calls without causing any side effects on the dependent resource state.
- In event consumers it is always safe to use eventId as the idempotentId of the API request allowing you to retry safely any number of times.
Example: Cancel an already cancelled order is idempotent across ECOS/OFS/QUOTE. so safe to retry any number of times.
2 Non Idempotent API services but support reading resource state: READ - VALIDATE - CALL
- Given the non idempotent nature , it is not safe to retry the request since it might result in errors, preventing u from recovering from errors.
- It is adviced to read the state of the dependent resource, validate the state and then make the call to the service if required.
- If the dependent state is already in the correct state/updated previsously, skip and continue to the next business step
- This approach will increase the latency of the request processing since we need to read the state of dependent service.
Example: Confirming a fulfilment slot. for instance if one cannot confirm an already confirmed slot which results in API failures. Hence read the state, check if it is confirmed and then decide if API needs to be called Similarly for payment APIs as well. We cannot charge an already charged card so, we need to read the state of the resource and take actions
3 Non Idempotent API service and no way to GET the resource state
- we do not want to be in this situation
- Resolution depends on a case by case basis
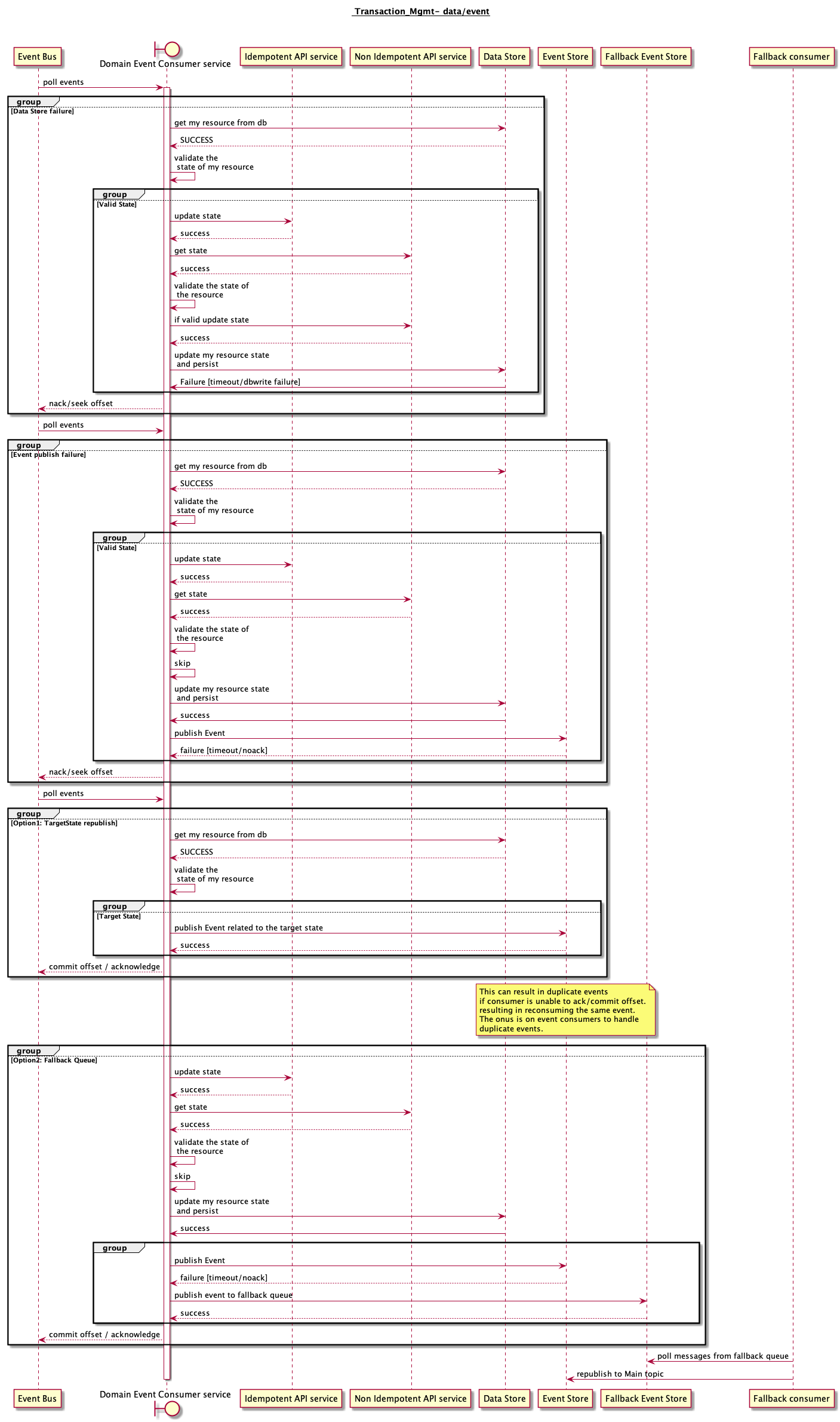
Ensuring Transactionality with data store and event store in case of failures
1 Target state- Republish Approach
- Given a request (new/retried)
- Read the state of the resource and if the resource is already in the target state emit an event for the given event/ API request.
- This might result in duplicate events if retried many times. Will work in atleast once semantics w.r.t events.
Example: if the order is already in the CheckedOut state and is stored in Couchbase, but failed to emit a checkout event, if the checkout API is retried, since the targetstate is already checkout, orderCheckout event is emited and a API success is returned.
Pros:
- Simple to implement and very reliable.
- No external dependencies since we rely only on the state of our resource
- Works well for event consumers since it can control the commit offset/acknowledge of events allowing u to achieve transactionality automatically.
Cons:
- APIs require retry to be done by consumers inorder to publish evenet and complete the transactionality.
- API Consumers apps/website will get an error in case of event publish failures which is not ideal reducing API availability.
2 Fallback Queue:
- It is important to ensure resiliency w.r.t event publish in kafka . [validate ISR, replication factor, broker fault tolerance, producer retries,timoeout handling]
- Despite all retries, In case of publish failures, we can publish into the fallback queue[DRkafka/SQS/EventBus] and reconcile into main topic in kafka.
Note the percentage of publish has to be very low. This is applicable mostly during kafka cluster level failures.
Pros:
- This will prevent API failures resulting in better API experience. for instance, Imagine order checkout failing just because we could not publish the checkout event into kafka topic.
Cons:
- We need additional fallback queue in place different from the main kafka cluster.
3 Resource and corresponding Events are stored atomically [data model change needed]
- Persist the Events related to state change alongside the resource in data store.
- Saving event & resource is a single operation, it is inherently atomic. Atomicity is ensured at the partitionkey level.
- Publish Events asynchronously
- Poll for any events from the data store and sync into event store marking the events as synced to prevent resyncing.
- Subscribe to Data Change protocol of the data store, and publish the event on change notification.
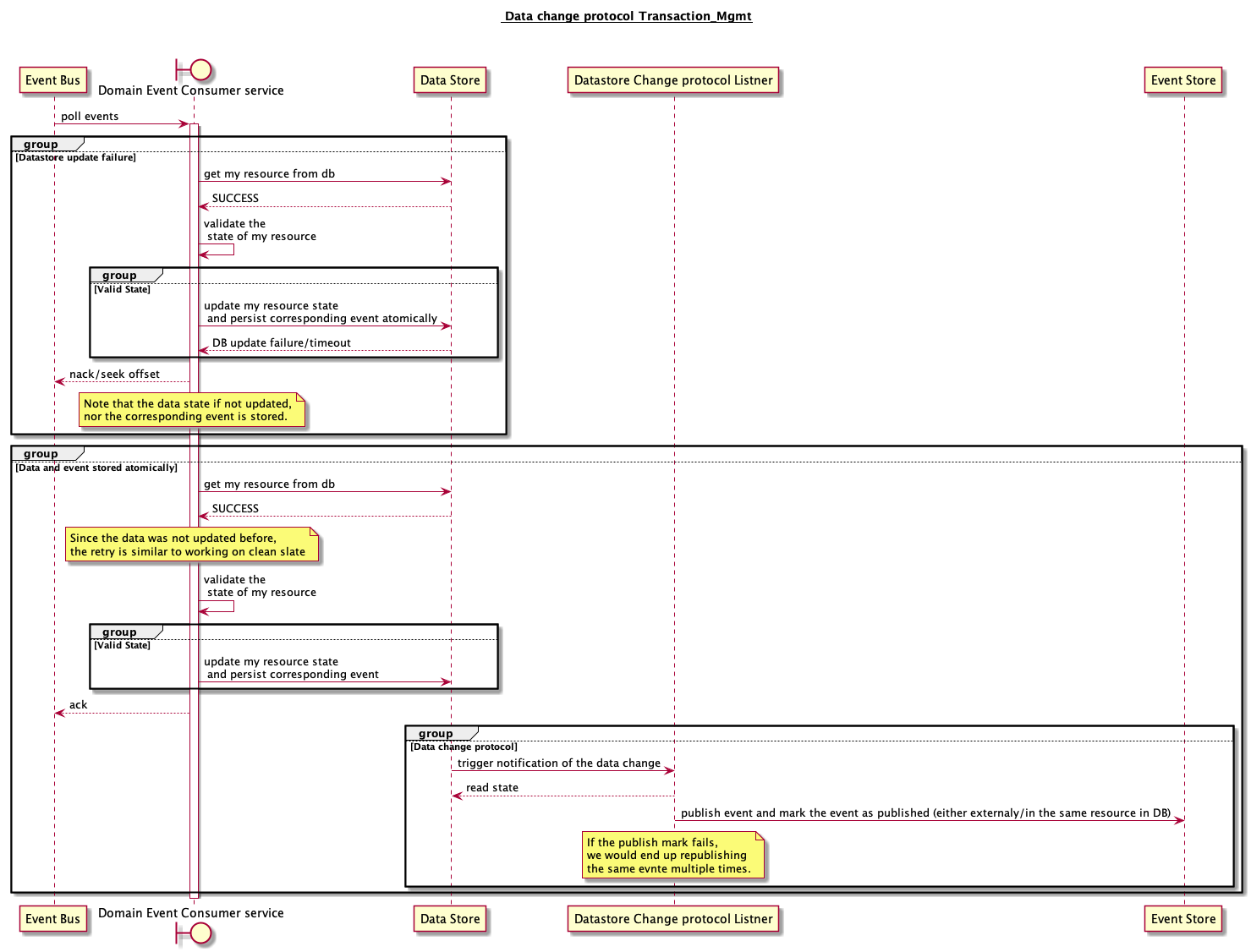
Pros:
- we get atomicity with resource and events since they are persisted together Cons:
- The main downside is the load on the data store due to polling.
- If the number of events generated are more, then the method is not ideal since the resource size can grow very quickly affecting ur reads and write performance.
4 Event Sourcing : [Data model changes needed]
- Final State of the resource is treated as a sequence of state-changing events.
- There is no resource as such in the data store, only events. The final state is created from the events during query.
Pros: Because it persists events rather than resource itself, it avoids the whole transactionality problem of resource and event being separate
Cons:
- Publish Events asynchronously either by polling or data change protocol
- The event store is difficult to query since it requires typical queries to reconstruct the state of the business entities. That is likely to be complex and inefficient.
- As a result, the application must use CQRS to implement queries. This in turn means that applications must handle eventually consistent data.
5 SAGA
- Prerequisite is Compensatory actions for every actions is needed in terms of API / DB calls
- The idea is to revert all actions that were taken before the failed step, to ensure is the system is left in clean state.
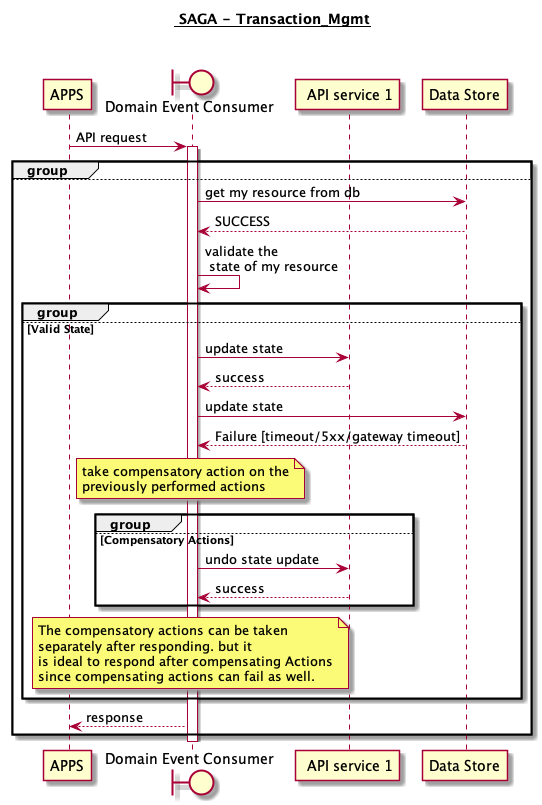 Pros:
Pros:
- Will leave the resource in a consistent state always. either it will be new state/old state but wont be in intermediate states.
Cons:
- Having compensatory actions for all API / Db calls is not feasible in most cases
The same approaches would work for APIs as well similar to event consumers. The difference is about who controls the retry in the recovery process.